Bei Fuzzy-Duplikaten handelt es sich um nahezu identische Zeichenwerte, die sich möglicherweise auf dieselbe tatsächliche Entität beziehen. Bei den folgenden vier Beispielwerten handelt es sich möglicherweise um dasselbe Unternehmen:
- Intercity Couriers
- Inter-city Couriers
- Intercity Couriers Inc.
- Intercity Couriers
Häufige Gründe für Fuzzy-Duplikate sind Fehler bei der Dateneingabe z.B. Tipp- und Rechtschreibfehler, unterschiedliche Methoden der Datenformatierung und unterschiedliche Eingabekonventionen für Daten. Nahezu identische Werte können auch aufgrund eines beabsichtigten Betrugs bewusst erstellt werden. Fuzzy-Duplikate behindern die Datenanalyse, die von der Konsistenz der Referenzdaten tatsächlicher Entitäten abhängt.
Fuzzy-Duplikate gegenüber Fuzzy-Zusammenführung
Das Feature der Fuzzy-Duplikate analysiert Werte in einem einzelnen Feld und einer einzelnen Analytics-Tabelle. Verwenden Sie die Fuzzy-Übereinstimmung, um Felder aus zwei Analytics-Tabellen in einer neuen dritten Tabelle zu vereinen. Siehe Fuzzy-Zusammenführung.
Funktionsweise
Mit dem Fuzzy-Duplikate-Feature in Analytics können Sie ein spezifisches Zeichenfeld in einer Tabelle testen, um Fuzzy-Duplikate innerhalb des Felds zu identifizieren. Die Ausgabeergebnisse gruppieren Fuzzy-Duplikate auf Grundlage des von Ihnen angegebenen Differenzgrads. Wenn Sie die Differenz anpassen, können Sie die Anzahl und die Größe der Ausgabegruppen sowie die Differenz zwischen Gruppenmitgliedern kontrollieren.
Um zu bestätigen, ob Elemente von Fuzzy-Duplikat-Gruppen in der echten Welt tatsächlich identisch sind, müssen Sie möglicherweise eine zusätzliche Analyse ausführen, z.B. einen Duplikattest für andere Felder als das Testfeld.
Hinweis
Das Testen auf Fuzzy-Duplikate ist komplexerer als die Suche nach exakten Duplikaten. Wenn Sie die Einstellungen zum Kontrollieren des Differenzgrads zwischen Fuzzy-Duplikaten und die Gruppierung von Fuzzy-Duplikaten in den Ausgabeergebnissen verstehen, können Sie die Funktion effizienter nutzen.
Ausgabeergebnisse für Fuzzy-Duplikate
Das folgende Beispiel zeigt die Ergebnisse des Tests von Fuzzy-Duplikaten im Feld Nachname einer Tabelle.
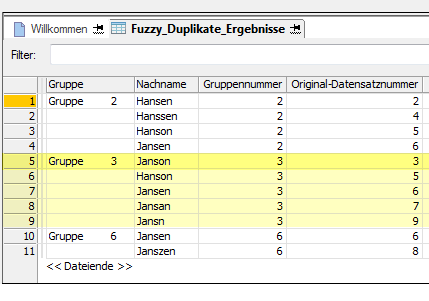
Die Ausgabeergebnisse werden in Gruppen 2, 3 und 6 angeordnet. Die Bezeichnung jeder Gruppe richtet sich nach der Ursprünglichen Datensatznummer des ersten Fuzzy-Duplikats der Gruppe. „Janson“ ist beispielsweise der Name in Datensatz 3 der Originaltabelle, und da es sich bei „Janson“ gemäß der Datensatzreihenfolge in der Originaltabelle um den ersten Wert der Gruppe handelt, wird die Gruppe als Gruppe 3 bezeichnet. Weitere Informationen finden Sie unter Gruppierung von Fuzzy-Duplikaten.
Die Funktion für Fuzzy-Duplikate verwendet zeichenbasierten Vergleich
Beim Vergleichen von zwei Werten wird von der Funktion für Fuzzy-Duplikate ein zeichenbasierter und kein wortbasierter Vergleich ausgeführt. Leerzeichen zwischen Wörtern werden von der Funktion als Zeichen behandelt, und es wird nicht zwischen einzelnen Wörtern unterschieden. Unabhängig von der Anzahl der einzelnen Wörter eines Werts wird der Wert von der Funktion als eine einzelne, ununterbrochene Zeichenfolge behandelt.
Aus diesem Ansatz ergibt sich, dass einige Werte, die wir Menschen wohl als Fuzzy-Duplikate kategorisieren würden, wegen der Beschaffenheit der Daten und aufgrund der Differenzeinstellungen, die Sie im Dialogfeld Fuzzy-Duplikate festgelegt haben, möglicherweise nicht in den Ausgabeergebnissen enthalten sind.
Beispiel
Betrachten Sie diese Namen:
- „JW Smith“ und „John William Smith“
- „Diamond Tire“ und „Diamond Tire & Auto“
Bei dem ersten Beispiel könnte es sich um zwei Versionen desselben Namens handeln, der im ersten Fall mit Initialen, im zweiten mit vollständigem Vornamen und zweitem Vornamen geschrieben ist. Das zweite Beispiel könnte die Kurz- bzw. Langversion eines Firmennamens sein.
Keines dieser beiden Namenpaare wird als Fuzzy-Duplikat zurückgegeben, sofern die Differenzeinstellungen nicht sehr weit gefasst sind, was den negativen Effekt hätte, dass auch eine große Anzahl Falschmeldungen zurückgegeben würde.
Die Funktion für Fuzzy-Duplikate verarbeitet jedes Namenpaar nur als zwei Zeichenfolgen. Da im jeweiligen Beispiel die beiden Zeichenfolgen eine signifikant unterschiedliche Länge aufweisen, werden sie auf Zeichenebene als signifikant unterschiedlich angesehen.
Weitere Informationen finden Sie unter Funktionsweise der Differenzeinstellungen.
Wirkung von Fuzzy-Duplikat-Analyse verbessern
Zusätzlich zur Hauptfunktion für Fuzzy-Duplikate sollten Sie möglicherweise die Größe des Testdatasets anpassen, die Hilfsfunktionen für Fuzzy-Duplikate verwenden oder Testfelder verketten, um die gewünschten Ergebnisse zu erzielen.
Die folgende Tabelle fasst die unterschiedlichen Techniken zusammen, mit denen die Wirkung von Fuzzy-Duplikat-Analysen verbessert werden.
Weitere Informationen über die Hilfsfunktion finden Sie unter Hilfefunktionen für Fuzzy-Duplikate.
|
Technik |
Analytics-Funktion |
Details |
|---|---|---|
|
Begrenzen der Größe des Testdatensatzes |
Filter Extrahieren von Datenuntergruppen |
Ausführungszeit verringen durch ausschließliche Verarbeitung von Datensätzen, die für Ihre Analyse sinnvoll sind |
| Einzelne Elemente in Testfeldwerten sortieren |
SORTWORDS( )-Funktion |
Größe der Ergebnisse verringern und ihre Genauigkeit verbessern, indem die Bedeutung der physischen Position einzelner Elemente in Testwerten minimiert wird Hinweis Obwohl das Fuzzy-Duplikat-Feature einen zeichenbasierten Vergleich durchführt, hat eine Sortierung von Wörtern in Testwerten den Vorteil, die Zeichen der zu vergleichenden Zeichenfolgen besser aneinander auszurichten. |
|
Generische Elemente aus Testfeldwerten entfernen |
OMIT( )-Funktion |
Verringerung des Umfangs von Ergebnissen und Steigerung ihrer Genauigkeit durch Konzentration auf den Teil der Zeichenwerte, in dem möglicherweise wichtige Differenzen auftreten |
|
Felder zur Erhöhung der Eindeutigkeit der Testwerte verketten |
Analytics-Ausdruck, der einen Und-Operator (+) verwendetAnalytics |
Verringerung des Umfangs von Ergebnissen und Steigerung ihrer Genauigkeit durch Testen von eindeutigeren, durch Verketten von mehreren Feldern erstellten Werten |
|
Eine einzige, vollständige Liste der Fuzzy-Duplikate für einen spezifischen Wert in den Ausgabeergebnissen generieren |
ISFUZZYDUP( )-Funktion |
Komfortable und vollständige Liste von Fuzzy-Duplikaten für einen Ausgabewert mit besonderer Relevanz für Ihr Analyseziel erstellen |
Sollte ich das Testfeld sortieren?
Zum Testen eines Felds auf Fuzzy-Duplikate muss das Feld nicht sortiert sein. Das Sortieren eines Testfelds vor dem Testen begünstigt die Wirksamkeit der Fuzzy-Duplikate-Operation in keiner Weise. Möglicherweise sortieren Sie ein Feld dennoch vor dem Testen, da Sie auf diese Weise übersichtlichere Ausgabeergebnisse erhalten und das Dialogfeld Fuzzy-Duplikate nicht über die Option Vorsortieren verfügt.
Hinweis
Obwohl ein Sortieren der Testfeldwerte die Wirksamkeit nicht steigert, kann das Sortieren einzelner Elemente in Feldwerten, die mehrere Elemente enthalten (z.B. Adressen), die Wirksamkeit beträchtlich verbessern. Weitere Informationen finden Sie unter Hilfefunktionen für Fuzzy-Duplikate.
Exakte Duplikate einbeziehen
Beim Testen auf Fuzzy-Duplikate können Sie in die Ausgabeergebnisse optional exakte Duplikate einbeziehen. Wenn Sie ausschließlich nach exakten Duplikaten suchen möchten, verwenden Sie die Funktion für Duplikate. Weitere Informationen finden Sie unter Prüfen auf Duplikate.