Konzept-Informationen
Die Analytics-Fuzzy-Zusammenführung verwendet eine Fuzzy-Übereinstimmung von Schlüsselfeldwerten, um zwei Analytics-Tabellen in einer neuen dritten Tabelle zu vereinen. In vielerlei Hinsicht entspricht eine Fuzzy-Zusammenführung einer gewöhnlichen Analytics-Zusammenführung (siehe Zusammenführen von Tabellen). Der Hauptunterschied besteht darin, dass Datensätze nicht nur auf Basis einer genauen Übereinstimmung von Schlüsselfeldwerten zusammengeführt werden. Eine Fuzzy-Zusammenführung kann Datensätze auch auf Basis einer ähnlichen Übereinstimmung zusammenführen.
Eine Fuzzy-Zusammenführung ist nützlich, wenn Primär- und Sekundärschlüssel dieselben Datenarten in leicht unterschiedlicher Ausprägung enthalten. Möglicherweise gibt es in den Schlüsseldaten auch leichte Unregelmäßigkeiten, wie beispielsweise Tippfehler, die eine genaue Übereinstimmung verhindern.
Beispiel
Szenario
Sie möchten Lieferanten identifizieren, die auch Mitarbeiter sind. Dies ist eine Möglichkeit, um Daten auf möglicherweise unangemessene Zahlungen zu analysieren.
Ansatz
Sie führen die Lieferantenstammtabelle mit der Tabelle „Mitarbeiter“ zusammen und verwenden dabei das Adressfeld, das in beiden Tabellen als gemeinsamer Schlüssel existiert (Vendor_Street und Emp_Address). Das Format der Adressdaten weicht in den Schlüsselfeldern aber leicht ab. Daher verwenden Sie statt einer normalen Zusammenführung die Fuzzy-Zusammenführung.
Ein Blick auf einige der Daten
Ohne eine beträchtliche Datenbereinigung und -harmonisierung würden die folgenden Primär- und Sekundärschlüsselwerte durch eine normale Analytics-Zusammenführung nicht zusammengeführt werden, obwohl sie sehr wahrscheinlich übereinstimmen.
| Primärschlüsselwerte | Sekundärschlüsselwerte |
|---|---|
| 605 3rd Avenue | 605 Third Avenue |
| 400 High St SE | 400 High Street S.E. |
| 2203 Rowan Street | 2203 Rowen St |
Selbst nach einer Datenbereinigung und -harmonisierung würden Schlüsselwerte mit leicht unterschiedlichen Schreibweisen, wie „Rowan“ und „Rowen“ wahrscheinlich nicht zusammengeführt werden.
Je nach den Einstellungen könnten die Schlüsselwerte jedoch durch eine Fuzzy-Zusammenführung zusammengeführt werden.
Ausgabeergebnisse
Im folgenden Beispiel der zusammengeführten Tabelle sind genaue Schlüsselfeldübereinstimmungen lila und Fuzzy-Übereinstimmungen grün hervorgehoben.
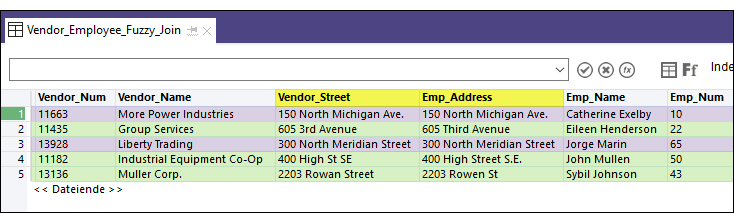
Fuzzy-Zusammenführung gegenüber Fuzzy-Duplikaten
Eine Fuzzy-Zusammenführung analysiert Werte in Schlüsselfeldern zweier Tabellen. Um ein einzelnes Feld in einer einzelnen Analytics-Tabelle auf fast identische Werte zu testen, siehe Fuzzy-Duplikate-Analyse.
Wirkung von Fuzzy-Zusammenführung verbessern
Mithilfe der folgenden Techniken können Sie die Wirksamkeit der Fuzzy-Zusammenführung beträchtlich steigern:
- Einzelne Elemente in den Werten der Primär- und Sekundärschlüsselfelder sortieren
- Generische Elemente aus den Werten der Primär- und Sekundärschlüsselfelder entfernen
- Werte von Primär- und Sekundärschlüsselfeldern harmonisieren
Durch diese Techniken können Sie striktere Fuzzy-Einstellungen verwenden und dieselben Fuzzy-Übereinstimmungen erhalten, während Sie die Anzahl der Falschmeldungen verringern. Sie können die Techniken separat oder zusammen verwenden.
Ausdruck oder Kalkulationsfeld erstellen
Um die Techniken zu verwenden, müssen Sie einen Ausdruck oder ein Kalkulationsfeld erstellen. Dazu verwenden Sie die jeweilige Analytics-Funktion und eines oder beide Schlüsselfelder.
Weitere Informationen über Ausdrücke finden Sie unter Verwenden von Ausdrücken.
Weitere Informationen über Kalkulationsfelder finden Sie unter Kalkulationsfelder definieren.
Notiz
Das Dialogfeld Fuzzy-Zusammenführung ermöglicht keine Erstellung eines Ausdrucks für ein Sekundärschlüsselfeld. Sie können jedoch einen Ausdruck für ein Sekundärschlüsselfeld manuell in der Analytics-Befehlszeile oder in einem Skript erstellen. Eine andere Option ist das Erstellen eines Kalkulationsfelds, das als Sekundärschlüsselfeld verwendet wird.
Einzelne Elemente in Schlüsselfeldwerten sortieren
Die Funktion SORTWORDS( ) kann die Wirksamkeit der Fuzzy-Zusammenführung verbessern, indem sie einzelne Elemente von Primär- und Sekundärschlüsselfeldern sequenziell sortiert.
Durch das Sortieren von Elementen, zum Beispiel Komponenten einer Adresse, ist es möglich, dass sich Schlüsselfeldwerte mit denselben Informationen, die ein unterschiedliches Format aufweisen, stärker angleichen. Eine stärkere Angleichung steigert die Wahrscheinlichkeit, dass Schlüsselfeldwerte als Fuzzy-Übereinstimmungen ausgewählt werden.
Weitere Informationen finden Sie unter SORTWORDS( )-Funktion.
Das Video Fuzzy Matching Using SORTWORDS() (Fuzzy-Übereinstimmungen mit SORTWORDS, nur auf Englisch) verschafft Ihnen einen Überblick zu SORTWORDS().
Notiz
Das Sortieren von Elementen in Schlüsselfeldwerten eignet sich am besten bei einer Fuzzy-Zusammenführung nach dem Levenshtein-Distanz-Algorithmus.
Bei einer Fuzzy-Zusammenführung mit dem Dice-Koeffizient-Algorithmus muss das Sortieren von Elementen nicht unbedingt hilfreich sein. Testen Sie Beispieldaten, bevor Sie entscheiden, ob Sie SORTWORDS( ) in einer Produktionsumgebung zusammen mit dem Dice-Koeffizient-Algorithmus verwenden möchten.
Achtung
Wenn Sie SORTWORDS( ) zusammen mit Fuzzy-Zusammenführung verwenden, müssen Sie SORTWORDS( ) auf beide zu vergleichende Zeichenfolgen oder Felder anwenden.
Generische Elemente aus den Schlüsselfeldwerten entfernen
Die OMIT( )-Funktion kann die Effektivität der Fuzzy-Zusammenführung verbessern, indem generische Elemente wie „GmbH“ oder „AG“ bzw. Zeichen wie Kommas, Punkte und das Kaufmannsund (&) aus den Werten der Primär- und Sekundärschlüsselfelder entfernt werden.
Durch das Entfernen generischer Elemente und Satzzeichen konzentriert sich die Fuzzy-Zusammenführung nur auf den Teil der Schlüsselfeldwerte, in dem aussagekräftige Unterschiede auftreten könnten.
Weitere Informationen finden Sie unter OMIT( )-Funktion.
Schlüsselfeldwerte harmonisieren
Die Funktionen REPLACE( ) oder REGEXREPLACE( ) können die Wirksamkeit der Fuzzy-Zusammenführung verbessern, indem sie variable Ausprägungen desselben Elements der Werte von Primär- und Sekundärschlüsselfelder harmonisieren. Zum Beispiel könnten Sie „Straße“, „Str.“ und „Str“ auf denselben Wert „Str“ harmonisieren.
Durch die Harmonisierung von Elementen ist es möglich, dass sich Schlüsselfeldwerte mit denselben Informationen, die ein unterschiedliches Format aufweisen, stärker angleichen. Eine stärkere Angleichung steigert die Wahrscheinlichkeit, dass Schlüsselfeldwerte als Fuzzy-Übereinstimmungen ausgewählt werden.
Weitere Informationen finden Sie unter REPLACE( )-Funktion für einfache Ersetzungen und unter REGEXREPLACE( )-Funktion für komplexere Ersetzungen.
Größe der Ausgabetabelle und Befehlsperformance
Größe der Ausgabetabelle
Die Fuzzy-Zusammenführung ähnelt der Analytics-n:n-Zusammenführung. Alle Primärschlüsselwerte können potenziell mit allen Sekundärschlüsselwerten abgeglichen werden. Die Größe der Ausgabetabelle kann um ein Vielfaches größer als die Größe der Primär- oder Sekundäreingabetabellen sein.
Befehlsperformance
Die Algorithmen für die Fuzzy-Übereinstimmung stellen sicher, dass nur Schlüsselwerte im Bereich eines bestimmten Fuzzy-Grades oder genau übereinstimmende Werte zusammengeführt werden. Jede mögliche Übereinstimmung zwischen Primär- und Sekundärwert muss jedoch getestet werden, weshalb die Fuzzy-Zusammenführung zeitaufwendig sein kann. Die Anzahl der durchzuführenden Einzeltests entspricht der Datensatzanzahl in der Primärtabelle multipliziert mit der Datensatzanzahl in der Sekundärtabelle.
Abgleich auf ersten übereinstimmenden Sekundärdatensatz beschränken
Sie können die Verarbeitungszeit und die Größe der Ausgabeergebnisse beträchtlich verringern, wenn Sie die Option Nur erstes Vorkommen übereinstimmender Sekundärschlüssel zusammenführen verwenden. Durch diese Option wird festgelegt, dass jeder Primärschlüsselwert lediglich mit dem ersten Vorkommen eines übereinstimmenden Sekundärschlüsselwerts zusammengeführt wird.
In einer der folgenden Situationen empfiehlt es sich, die Option zu aktivieren:
- Übereinstimmungen vorhanden? Sie möchten nur wissen, ob es in den beiden Tabellen überhaupt Übereinstimmungen (genaue oder Fuzzy-Übereinstimmungen) gibt. Gleichzeitig möchten Sie nicht warten, bis alle Übereinstimmungen ermittelt wurden.
- Höchstens eine Übereinstimmung Sie sind sicher, dass es höchstens eine Übereinstimmung in der Sekundärtabelle für jeden Primärschlüsselwert gibt.
Die Aktivierung der Option empfiehlt sich nicht, wenn Sie Ausgabeergebnisse mit allen möglichen Übereinstimmungen zwischen Primär- und Sekundärschlüsselwerten benötigen.
Notiz
Falls Sie Nur erstes Vorkommen übereinstimmender Sekundärschlüssel zusammenführen auswählen und das erste Vorkommen eine genaue Übereinstimmung ist, werden alle folgenden Fuzzy-Übereinstimmungen für den Primärschlüsselwert nicht in die zusammengeführte Ausgabetabelle aufgenommen.
Empfohlene Vorgehensweisen
Beachten Sie die Größe der Ausgabetabelle und die Befehlsperformance, wenn Sie die Primär- und Sekundäreingabetabellen vorbereiten und den Fuzzy-Grad festlegen.
- Daten maßschneidern Stellen Sie sicher, dass nur relevante Datensätze in den Primär- und Sekundärtabellen aufgenommen werden. Wenn einige Datensätze keine Chance einer Übereinstimmung haben, filtern Sie sie vor der Durchführung der Fuzzy-Übereinstimmung aus.
- Testläufe Bei großen Datasets führen Sie Testläufe für einen kleinen Teil der Daten durch, um die geeigneten Einstellungen für die Algorithmen der Fuzzy-Übereinstimmung effizienter zu ermitteln. Beginnen Sie mit konservativeren Fuzzy-Einstellungen und lockern Sie sie bei Bedarf.
Algorithmen für die Fuzzy-Übereinstimmung
Wenn Sie eine Fuzzy-Zusammenführung durchführen, wählen Sie zwischen zwei Algorithmen für die Fuzzy-Übereinstimmung:
- Dice-Koeffizient
- Levenshtein-Distanz
Die Algorithmen funktionieren völlig unabhängig voneinander und können zu etwas unterschiedlichen Ergebnissen führen. Ein Ansatz ist die doppelte Durchführung einer Fuzzy-Zusammenführung, einmal mit jedem Algorithmus, und dem anschließenden Vergleich der Ergebnisse. In der Regel kommt es zu einer Überlappung von Fuzzy-Übereinstimmungen beider Ergebnismengen, einige Übereinstimmungen können aber in jeder Ergebnismenge nur einmal vorkommen.
Fuzzy-Grad
Sie legen den Fuzzy-Grad für jeden Algorithmus fest, was die Größe und Zusammensetzung der Ergebnismenge drastisch ändern kann. „Fuzzy-Grad“ bezieht sich darauf, wie stark zwei Werte übereinstimmen.
Je nach gewähltem Algorithmus verwenden Sie die folgenden Einstellungen zur Steuerung des Fuzzy-Grads:
| Algorithmus | Einstellung |
|---|---|
|
Dice-Koeffizient |
|
|
Levenshtein-Distanz |
|
Versuchen Sie, mit unterschiedlichen Fuzzy-Graden zu experimentieren. Beginnen Sie konservativ, und erstellen Sie kleinere Ergebnismengen. Lockern Sie dann graduell die Einstellungen, bis Sie zu viele zusammengeführte Werte erhalten, die offensichtlich keine Übereinstimmungen mehr sind (Falschmeldungen).
Dice-Koeffizient
Der Algorithmus „Dice-Koeffizient“ misst die Ähnlichkeit zwischen dem Primär- und Sekundärschlüsselwert auf einer Skala von 0,0000 bis 1,0000. Je größer der Dice-Koeffizient der beiden Werte ist, umso ähnlicher sind sie sich.
| Dice-Koeffizient | Bedeutung |
|---|---|
| 1,0000 |
Jeder Wert setzt sich aus identischen Zeichen zusammen, obwohl die Zeichen womöglich unterschiedlich angeordnet sind und sich die Groß- und Kleinschreibung unterscheiden kann. Die N-Gramme der beiden Werte sind zu 100% identisch. N-Gramme werden im Folgenden erläutert. |
| 0,7500 |
Die N-Gramme der beiden Werte sind zu 75% identisch. |
| 0,0000 | Die beiden Werte enthalten keine identischen N-Gramme oder die festgelegte Länge der Einstellung N-Gramm ist länger als die kürzere der beiden Vergleichszeichenfolgen. |
N-Gramme
Der Dice-Koeffizient wird berechnet, indem die zu vergleichenden Werte zuerst in N-Gramme aufgeteilt werden. N-Gramme sind sich überlappende Zeichenblöcke mit der Länge N. „N“ ist die Länge, die Sie in der Einstellung N-Gramm festlegen.
Es folgen zwei Werte aus dem obigen Beispiel, die in N-Gramme der Länge von 2 Zeichen aufgeteilt sind (N=2).
| Wert | N-Gramme |
|---|---|
| 2203 Rowan Street | 22 | 20 | 03 | 3_ | _R | Ro | ow | wa | an | n_ | _S | St | tr | re | ee | et |
| 2203 Rowen St | 22 | 20 | 03 | 3_ | _R | Ro | ow | we | en | n_ | _S | St |
Der Dice-Koeffizient entspricht dem Prozentsatz identischer N-Gramme der beiden Werte. In diesem Fall sind 20 von 28 N-Grammen identisch. Dies sind 71,43% oder 0,7143 als Dezimalzahl.
Notiz
Wenn die Länge in der Einstellung N-Gramm angehoben wird, wird die Ähnlichkeit der beiden Werte strikter bewertet.
Prozent
Wenn Sie die Einstellung Prozent festlegen, stellen Sie den zulässigen Mindestwert des Dice-Koeffizienten zweier Werte ein, sodass diese als Fuzzy-Übereinstimmung gelten. Wenn Sie beispielsweise 0.7500 angeben, müssen mindestens 75 % der N-Gramme von zwei Werten identisch sein, damit eine Übereinstimmung vorliegt.
| Prozenteinstellung | Bedeutung | 2203 Rowan Street / 2203 Rowen St |
|---|---|---|
| 0,7500 |
Um als Fuzzy-Übereinstimmung zu gelten, müssen mindestens 75% der N-Gramme von zwei Werten identisch sein. |
Keine Übereinstimmung, nicht in zusammengeführter Tabelle enthalten (Dice-Koeffizient = 0,7143) |
| 0,7000 |
Um als Fuzzy-Übereinstimmung zu gelten, müssen mindestens 70% der N-Gramme von zwei Werten identisch sein. |
Übereinstimmung, in zusammengeführter Tabelle enthalten (Dice-Koeffizient = 0,7143) |
Detaillierte Informationen über die Funktionsweise des Dice-Koeffizienten finden Sie unter DICECOEFFICIENT( )-Funktion.
Levenshtein-Distanz
Der Algorithmus „Levenshtein-Distanz“ misst den Unterschied zwischen einem Primär- und Sekundärschlüsselwert auf einer ganzzahligen Skala, die mit 0 beginnt. Die Skala stellt die Anzahl von Bearbeitungen einzelner Zeichen dar, die erforderlich sind, um einen Wert auf einen anderen Wert zu überführen. Je größer die Levenshtein-Distanz der beiden Werte ist, umso unterschiedlicher sind sie.
| Levenshtein-Distanz | Bedeutung |
|---|---|
| 0 | Jeder Wert setzt sich aus identischen Zeichen in identischer Anordnung zusammen. Die Groß- und Kleinschreibung kann abweichen. |
| 2 |
Es ist die Bearbeitung von zwei Zeichen notwendig, damit die Werte identisch sind. Beispiel: „Smith“ und „Smythe“
|
| 1 |
Es ist die Bearbeitung von drei Zeichen notwendig, damit die Werte identisch sind. Beispiel: „Hanssen“ und „Jansn“
|
Abstand
Wenn Sie die Einstellung Distanz festlegen, stellen Sie den zulässigen Maximalwert der Levenshtein-Distanz zweier Werte ein, sodass diese als Fuzzy-Übereinstimmung gelten. Wenn Sie zum Beispiel 2 festlegen, dürfen nicht mehr als zwei Bearbeitungen notwendig sein, bis die beiden Werte identisch sind.
| Einstellung „Distanz“ | Bedeutung | Hanssen / Jansn |
|---|---|---|
| 2 |
Um als Fuzzy-Übereinstimmung zu gelten, dürfen nicht mehr als zwei Zeichenbearbeitungen notwendig sein, bis die beiden Werte identisch sind. |
Keine Übereinstimmung, nicht in zusammengeführter Tabelle enthalten (Levenshtein-Distanz = 3) |
| 1 |
Um als Fuzzy-Übereinstimmung zu gelten, dürfen nicht mehr als drei Zeichenbearbeitungen notwendig sein, bis die beiden Werte identisch sind. |
Übereinstimmung, in zusammengeführter Tabelle enthalten (Levenshtein-Distanz = 3) |
Detaillierte Informationen über die Funktionsweise der Levenshtein-Distanz finden Sie unter LEVDIST( )-Funktion. Im Gegensatz zur Funktion schneidet der Algorithmus der Levenshtein-Distanz bei der Fuzzy-Zusammenführung führende und nachgestellte leere Werte ab und beachtet keine Groß-/Kleinschreibung.
Schritte
Sie können eine Fuzzy-Übereinstimmung von Schlüsselfeldwerten verwenden, um zwei Analytics-Tabellen in einer neuen dritten Tabelle zu vereinen.
Notiz
Detaillierte Informationen werden nach den Schritten angezeigt. Siehe Optionen im Dialogfeld „Fuzzy-Zusammenführung“
- Öffnen Sie im Navigator die Primärtabelle und klicken Sie mit der rechten Maustaste auf die Sekundärtabelle. Wählen Sie Als Sekundärtabelle öffnen.
Die Symbole der Primär- und Sekundärtabelle erhalten die Ziffern 1 und 2, um ihre Beziehung zueinander darzustellen

 .
. - Wählen Sie Daten > Fuzzy-Zusammenführung.
- Auf der Registerkarte Haupt wählen Sie den Algorithmus der Fuzzy-Übereinstimmung aus, den Sie nutzen möchten.
- Dice-Koeffizient
- Levenshtein
- Je nach gewähltem Algorithmus verwenden Sie Einstellungen zur Steuerung des Fuzzy-Grads:
Dice-Koeffizient
- N-Gramm
- Prozent
Levenshtein
- Abstand
Die Einstellungen werden im Folgenden erläutert.
- (Optional) Wählen Sie Nur erstes Vorkommen übereinstimmender Sekundärschlüssel zusammenführen, um festzulegen, dass jeder Primärschlüsselwert lediglich mit dem ersten Vorkommen eines übereinstimmenden Sekundärschlüsselwerts zusammengeführt wird.
- Wählen Sie das primäre Schlüsselfeld aus der Liste Primärschlüssel aus.
Sie können nur ein Primärschlüsselfeld wählen, das ein Zeichenfeld sein muss.
- Wählen Sie das sekundäre Schlüsselfeld aus der Liste Sekundärschlüssel aus.
Sie können nur ein Sekundärschlüsselfeld wählen, das ein Zeichenfeld sein muss.
- Wählen Sie in den Listen Primärfelder und Sekundärfelder die Felder aus, die in der zusammengeführten Tabelle enthalten sein sollen.
Notiz
Sie müssen die Primär- und Sekundärschlüsselfelder, die in der endgültigen Tabelle enthalten sein sollen, explizit auswählen.
Tipp
Sie können mehrere, nicht angrenzende Felder auswählen, indem Sie die Steuerungstaste gedrückt halten und auf die betreffenden Felder klicken. Halten Sie die Umschalttaste gedrückt, und klicken Sie auf angrenzende Felder, um diese auszuwählen.
- Geben Sie im Textfeld Nach den Namen der neuen, zusammengeführten Tabelle ein.
- (Optional) Auf der Registerkarte Weiter:
- Wenn Sie lediglich eine Teilmenge der Datensätze verarbeiten möchten, wählen Sie eine der Optionen unter Bereich.
- Wenn Sie die Ausgabeergebnisse an eine bereits vorhandene Analytics-Tabelle anhängen (hinzufügen) möchten, wählen Sie An diese Datei anhängen.
- Klicken Sie auf OK.
Die neue zusammengeführte Tabelle wird ausgegeben.
Optionen im Dialogfeld „Fuzzy-Zusammenführung“
Die folgenden Tabellen enthalten detaillierte Informationen über die Optionen im Dialogfeld Fuzzy-Zusammenführung.
Registerkarte „Haupt“
| Optionen – Dialogfeld „Fuzzy-Zusammenführung“ | Beschreibung |
|---|---|
| Dice-Koeffizient |
Verwenden Sie den Dice-Koeffizienten für Fuzzy-Übereinstimmungen zwischen Primär- und Sekundärschlüsselwerten.
|
| Levenshtein |
Verwenden Sie die Levenshtein-Distanz für Fuzzy-Übereinstimmungen zwischen Primär- und Sekundärschlüsselwerten.
|
| Nur erstes Vorkommen übereinstimmender Sekundärschlüssel zusammenführen |
Gibt an, dass jeder Primärschlüsselwert mit lediglich dem ersten Vorkommen eines Sekundärschlüsselwerts zusammengeführt wird. Wenn Sie die Option nicht auswählen, besteht das Standardverhalten darin, jeden Primärschlüsselwert mit allen Vorkommen übereinstimmender Sekundärschlüssel zusammenzuführen. |
| Sekundärtabelle | Eine alternative Methode zur Auswahl der Sekundärtabelle. |
| Primärschlüssel Sekundärschlüssel |
Legt das gemeinsame Schlüsselfeld zur Zusammenführung der beiden Tabellen fest.
Richtlinien für Schlüsselfelder:
|
| Primärfelder Sekundärfelder |
Gibt die Felder an, die in der zusammengeführten Tabelle enthalten sein sollen.
|
| Ausgabetabelle verwenden | Legt fest, dass die Analytics-Tabelle mit Ausgabeergebnissen automatisch nach dem Abschluss der Operation geöffnet wird. |
| Wenn |
(Optional) Ermöglicht Ihnen, eine Bedingung zu erstellen, um Datensätze von der Verarbeitung auszuschließen.
|
| An | Gibt den Namen und den Speicherort der Ausgabetabelle an.
Unabhängig davon, wo Sie die Ausgabetabelle speichern, wird diese zum geöffneten Projekt hinzugefügt, falls sie nicht bereits im Projekt vorhanden ist. Falls Analytics einen Tabellennamen vorgibt, können Sie diesen akzeptieren oder ändern. Notiz Analytics-Tabellennamen sind auf 64 alphanumerische Zeichen beschränkt, was die .FIL- Dateierweiterung nicht einbezieht. Der Name kann den Unterstrich beinhalten ( _ ), aber keine anderen Sonderzeichen oder Leerzeichen. Er kann nicht mit einer Ziffer beginnen. |
Registerkarte „Weiter“
| Optionen – Dialogfeld „Fuzzy-Zusammenführung“ | Beschreibung |
|---|---|
| Fensterbereich „Bereich“ | Legt fest, welche Datensätze in der Primärtabelle verarbeitet werden:
Notiz Die Anzahl der Datensätze, die mit den Optionen Erste oder Nächste festgelegt werden, beziehen sich entweder auf die physikalische oder die indizierte Reihenfolge der Einträge in einer Tabelle. Filter oder Schnellsortierung der Ansicht werden vernachlässigt. Bei Ergebnissen analytischer Operationen wird die vorhandene Filterung jedoch berücksichtigt. Wenn eine Schnellsortierung für die Ansicht angewandt wird, verhält sich die Option Nächste wie Erste. |
| An diese Datei anhängen | Legt fest, dass die Ausgabeergebnisse an das Ende einer bereits vorhandenen Analytics-Tabelle angehängt (hinzugefügt) werden sollen. Notiz Es wird empfohlen, An diese Datei anhängen nicht auszuwählen, wenn Sie unsicher sind, ob die Datenstruktur der Ausgabeergebnisse und der vorhandenen Tabelle übereinstimmen. Weitere Informationen zum Anhängen und zur Datenstruktur finden Sie unter Ausgabeergebnisse an bestehende Tabellen anhängen. |
| OK | Führt die Operation aus.
|