Como as duplicidades parciais são agrupadas
Ao processar dados, a operação de duplicidades parciais move o campo de teste sequencialmente para baixo. A operação compara o primeiro valor no campo com cada valor subsequente, depois compara o segundo valor no campo com cada valor subsequente, e assim por diante, percorrendo os campos até que os valores tenham sido comparados com cada valor subsequente. Ela não compara valores com valores anteriores.
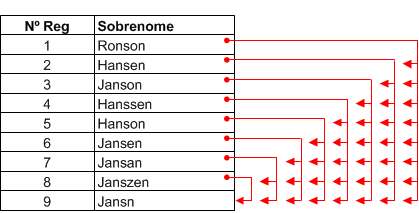
Com cada comparação, a operação determina se os dois valores comparados são duplicidades parciais com base nas configurações de diferenciação especificadas. (Para obter mais informações sobre configurações de diferenciação , consulte Como as configurações diferenciais funcionamdiferenciais funcionam.) Se os dois valores forem duplicidades parciais, eles são agrupados juntos. Resultados redundantes são suprimidos (explicado mais em frente nesse tópico). Os resultados de uma operação de duplicidades parciais podem conter vários grupos.
Proprietário do grupo e membros do grupo
A primeira duplicidade parcial em um grupo é o valor de controle ou "proprietário" do grupo, baseado exclusivamente no fato que entre os membros do grupo ele aparece primeiro no campo sendo testado. Um campo de teste que contém os mesmos dados, mas ordenados de forma diferente produzem proprietários de grupo e grupos constituintes diferentes.
O grupo é identificado usando o número de registro do proprietário do grupo. O exemplo abaixo mostra os resultados do testes de um campo Sobrenome. "Janson" forma um grupo (com base nas configurações de diferenciação) e é o registro número 3 na tabela original; portanto, o grupo se torna o Grupo 3.
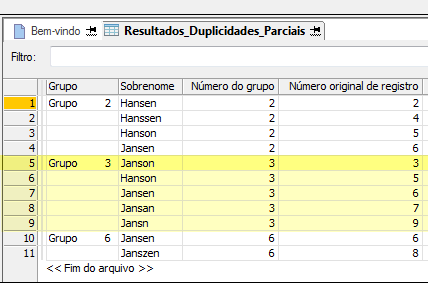
O proprietário do grupo não é necessariamente o valor correto
O proprietário do grupo não é necessariamente o valor "correto" ou canônico. Ele é simplesmente o valor no qual o grau de diferença especificado é medido ou calculado no processo da formação dos grupos. Todos os membros de um grupo estão dentro de um grau especificado de diferença do proprietário do grupo. Os membros podem ou não estar dentro de um grau especificado de diferença em relação aos outros.
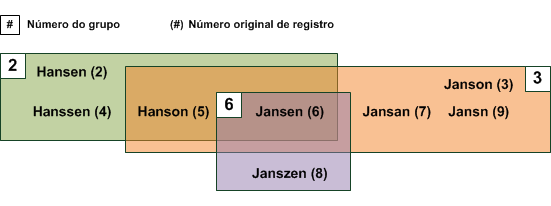
O diagrama abaixo fornece uma representação visual dos resultados na tabela de saída acima. O limite de diferença é 1, o que significa que os membros do grupo pode diferir do proprietário do grupo por no máximo um (1) caractere. Observe que algumas das duplicidades parciais aparecem em mais de um grupo.
Resultados exaustivos x não-exaustivos
Para que evitar resultados tornem-se grandes demais para serem gerenciados, o recurso de duplicidades parciais é projetado para produzir grupos que são não exaustivos. Não exaustivo significa que grupos de duplicidades parciais podem não conter todas as duplicidades parciais em um campo de teste que estão dentro de um grau especificado de diferença do proprietário do grupo. No entanto, se um proprietário do grupo é uma duplicidade parcial de outro valor no campo de teste, os dois valores aparecerão juntos em um grupo em alguma parte dos resultados, mas não necessariamente no grupo associado com o proprietário do grupo. Portanto, os grupos podem ser não exaustivos, mas os resultados, no total, são exaustivos.
Se produzir uma única lista exaustiva de duplicidades parciais de um valor específico no campo de teste for importante para sua análise, é possível usar a função ISFUZZYDUP( ) para isso. Para obter mais informações, consulte Funções do ajudante de duplicidades parciais.
Formação de grupos em detalhes
O recurso de duplicidades parciais cria grupos não exaustivos através da exclusão de valores de um grupo, caso eles apareçam com o proprietário do grupo em um grupo anterior. Essa abordagem de formação de grupos reduz o número de pares redundantes de duplicidades parciais e ajuda a controlar o tamanho geral dos resultados.
As regras que regem a formação de grupos são explicadas abaixo, com exemplos associados.
| Regra | Explicação |
|---|---|
| A relação proprietário-membro não é recíproca. |
Como a operação de duplicidades parciais move o campo de teste sequencialmente para baixo, os proprietários de grupo são associados com apenas essas duplicidades parciais que aparecem abaixo deles no campo, não com outras que apareçam acima. Em muitos casos, um proprietário de grupo é membro de um ou mais grupos que aparecem acima dele. No entanto, o inverso não é verdadeiro. Os proprietários de grupo acima não são membros do grupo subsequente. Uma vez que um valor se torna o proprietário de grupo, ele nunca aparece em um grupo subsequente. No exemplo acima, o proprietário do Grupo 6, "Jansen", é membro de dois grupos anteriores, mas os proprietários desses grupos ("Hansen" e "Janson"), mesmo sendo duplicidades parciais de "Jansen", não são membros do Grupo 6. |
| Se dois valores são membros de um grupo anterior, eles não são colocados juntos em um grupo subsequente se um desses valores for proprietário do grupo subsequente |
No exemplo acima, "Jansen", "Jansan" e "Jansn" são membros do Grupo 3. Quando “Jansen” torna-se proprietário do Grupo 6, “Jansan” e “Jansn” não são colocados no grupo, embora sejam ambos duplicidades parciais que aparecem abaixo de “Jansen” no campo de teste. |
| Se dois valores são membros de um grupo anterior, eles podem aparecer juntos em um grupo subsequente se nenhum desses valores for proprietário do grupo subsequente |
No exemplo acima, "Hanson" e "Jansen" aparecem juntos no Grupo 2 e Grupo 3. Nesse exemplo, aparecer juntos em mais de um grupo pode ocorrer porque o grau de diferença está sendo medido a partir dos respectivos proprietários de grupo, não a partir de cada um deles. |
Observação
Ocasionalmente, pode haver exceções à segunda e terceira regra. Durante a execução, a operação de duplicidades parciais armazena valores temporários. Se o espaço alocado para esses valores temporários forem preenchidos, o resultado pode ser alguns proprietários de grupo com um ou mais membros de grupo que são redundantes. (O proprietário e o membro apareceram juntos em um grupo anterior). Quanto menor o tamanho máximo especificado para grupos de duplicidades parciais, mais provavelmente essa redundância ocorrerá.
Processamento de dados de duplicidades parciais e formação de grupos
A tabela abaixo mostra o processamento do exemplo acima, registro por registro. Os dados são processados em sequência decrescente. Para diminuir a redundância, os valores são excluídos de um grupo se apareceram com o proprietário do grupo em um grupo anterior.
(Configurações de diferenciação: Limite de diferença = 1, Porcentagem de diferença = 99)
| Número do registro | Sobrenome | Duplicidades parciais encontradas | Resultados de saída |
|---|---|---|---|
|
1 |
Ronson |
|
|
|
2 |
Hansen |
Hanssen, Hanson, Jansen |
Grupo 2 Proprietário do grupo: Hansen Membros do grupo: Hanssen, Hanson, Jansen |
|
3 |
Janson |
Hanson, Jansen, Jansan, Jansn |
Grupo 3 Proprietário do grupo: Janson Membros do grupo: Hanson, Jansen, Jansan, Jansn |
|
4 |
Hanssen |
|
|
|
5 |
Hanson |
|
|
|
6 |
Jansen |
Jansan, Janszen, Jansn |
Grupo 6 Proprietário do grupo: Jansen Membros do grupo: Janszen |
|
7 |
Jansan |
Jansn |
|
|
8 |
Janszen |
|
|
|
9 |
Jansn |
|
|
Incluir duplicidades parciais nos resultados
Ao processar os dados, a operação de duplicidades parciais sempre inclui duplicidades exatas, mas as retira dos resultados, a menos que você selecione Incluir duplicidades exatas na caixa de diálogo Duplicidades parciais.
Duplicidades exatas estão sujeitas às mesmas regras de formação de grupo que as duplicidades parciais. Elas são excluídas de um grupo se apareceram com o proprietário do grupo em um grupo anterior. Se o proprietário do grupo e o valor excluído são duplicidades exatas, pode parecer que o valor excluído devesse estar no grupo do proprietário. No entanto, a exclusão é consistente com as regras de formação dos grupos, pois os dois valores já estiveram juntos em um grupo anterior.
A tabela abaixo mostra o processamento de duplicidades exatas. Os dados são processados em sequência decrescente.
- “Ronson (3)” não forma um grupo com“Ronson (4)”, pois os dois valores já estavam juntos no Grupo 1.
- “Jansen (9)” foi excluído do grupo formado por “Jansen (8)”, pois os dois valores já estavam juntos no Grupo 2 e Grupo 5.
(Configurações de diferenciação: Limite de diferença = 1, Porcentagem de diferença = 99, Incluir duplicidades exatas = S)
| Número do registro | Sobrenome | Duplicidades parciais e duplicidades exatas encontradas | Resultados de saída |
|---|---|---|---|
|
1 |
Ronson |
Ronson (3), Ronson (4) |
Grupo 1 Proprietário do grupo: Ronson Membros do grupo: Ronson (3), Ronson (4) |
|
2 |
Hansen |
Hanssen, Hanson, Jansen (8), Jansen (9) |
Grupo 2 Proprietário do grupo: Hansen Membros do grupo: Hanssen, Hanson, Jansen (8), Jansen (9) |
|
3 |
Ronson |
Ronson (4) |
|
|
4 |
Ronson |
|
|
|
5 |
Janson |
Hanson, Jansen (8), Jansen (9), Jansan, Jansn |
Grupo 5 Proprietário do grupo: Janson Membros do grupo: Hanson, Jansen (8), Jansen (9), Jansan, Jansn |
|
6 |
Hanssen |
|
|
|
7 |
Hanson |
|
|
|
8 |
Jansen |
Jansen (9), Jansan, Janszen, Jansn |
Grupo 8 Proprietário do grupo: Jansen Membros do grupo: Janszen |
|
9 |
Jansen |
Jansan, Janszen, Jansn |
Grupo 9 Proprietário do grupo: Jansen Membros do grupo: Janszen |
|
10 |
Jansan |
Jansn |
|
|
11 |
Janszen |
|
|
|
12 |
Jansn |
|
|