Use o aprendizado de máquina automatizado no Analytics para prever classes ou valores numéricos associados com dados não rotulados. Os dados são considerados não rotulados se as classes ou valores numéricos em que você está interessado não existem nos dados. Por exemplo, você pode usar o aprendizado de máquina para prever inadimplências de empréstimos ou preços futuros de residências:
| Problema de previsão | Tipo de previsão | Descrição |
|---|---|---|
| Inadimplências de empréstimos | Classificação |
Com base em informações dos solicitantes como idade, categoria do trabalho, pontuação de crédito e assim por diante, preveja quais solicitantes ficarão inadimplentes se receberem um empréstimo. Em outras palavras, os solicitantes ficarão na classe Inadimplência = Sim ou Inadimplência = Não? |
| Preços futuros de residências | Regressão | Com base em características como idade, área do imóvel, CEP, número de quartos e banheiros e assim por diante, preveja o preço futuro de venda de residências. |
Aprendizado de máquina automatizado
O aprendizado de máquina no Analytics é "automatizado" porque dois comandos relacionados, Treinar e Prever, executam todo o trabalho computacional associado ao treinamento e à avaliação de um modelo preditivo e à aplicação do modelo preditivo a um conjunto de dados não rotulado. A automação oferecida pelo Analytics permite aplicar o aprendizado de máquina em dados da empresa, sem que você tenha recursos especializados em ciência de dados.
O fluxo de trabalho de treinamento e previsão
O fluxo de trabalho de treinamento e previsão consiste em dois processos relacionados e dois conjuntos de dados relacionados:
- O processo de treinamento usa um conjunto de dados de treinamento (rotulado)
- O processo de previsão usa um novo conjunto de dados de treinamento (não rotulado)
Processo de treinamento
O processo de treinamento é executado antes, usando um conjunto de dados de treinamento que inclui um campo rotulado (também denominado um campo de destino).
O campo rotulado contém a classe conhecida, ou o valor numérico conhecido, associado a cada registro no conjunto de dados de treinamento. Por exemplo, se um tomador ficou inadimplente em um empréstimo (S/N) ou o preço de venda de uma casa.
Usando algoritmos de aprendizado de máquina, o processo de treinamento gera um modelo preditivo. O processo de treinamento gera diversas permutações de modelos diferentes para descobrir o modelo mais adequado à tarefa preditiva que você está realizando.
Processo de previsão
Em seguida, é executado o processo de previsão. Esse processo aplica o modelo preditivo gerado pelo processo de treinamento a um conjunto de dados novo e não rotulado que contém dados similares aos dados no conjunto de dados de treinamento.
Os valores de rótulos, como informações de inadimplência de empréstimos ou preço de venda de casas, não existem no novo conjunto de dados porque são eventos futuros.
Usando o modelo preditivo, o processo de previsão prevê uma classe ou valor numérico associado a cada registro não rotulado no novo conjunto de dados.
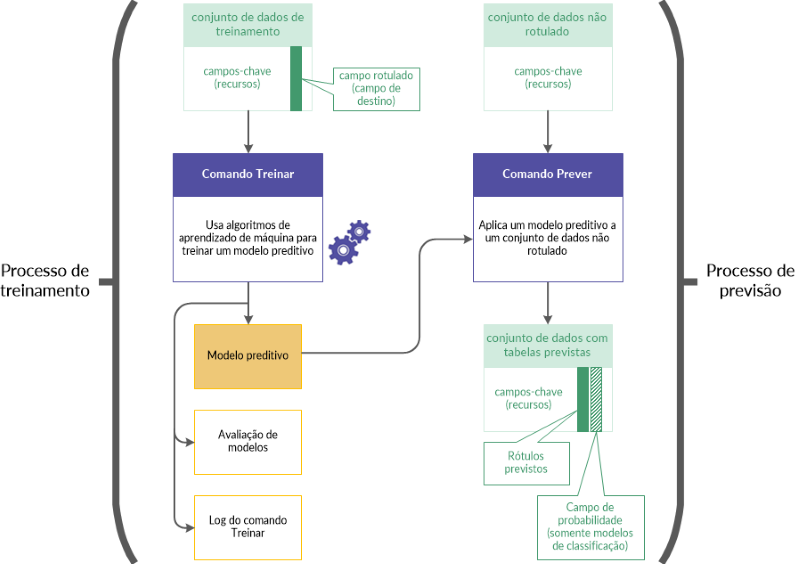
O fluxo de trabalho de treinamento e previsão em mais detalhes
| Sequência | Processar | Descrição | Exemplos de conjuntos de dados |
|---|---|---|---|
| 1 |
Treinamento (Comando Treinar) |
|
|
| 2 |
Previsão (Comando Prever) |
|
|
Tempo de processamento
A computação necessária para o aprendizado de máquina é demorada e faz uso intensivo dos processadores. O treinamento de um modelo preditivo usando um conjunto de dados grande com vários campos pode levar horas e, normalmente, é uma tarefa executada durante a noite.
A inclusão de campos-chave datahora no processo de treinamento aumenta consideravelmente o uso do processador, pois para cada campo data hora são derivados automaticamente 10 recursos sintéticos. Os recursos sintéticos de datahora podem aumentar substancialmente o escopo dos dados preditivos, mas você somente deve incluir campos data horas se acreditar que sejam relevantes.
Dica
Se você está começando a se familiarizar com o aprendizado de máquina no Analytics, use conjuntos de dados pequenos para manter os tempos de processamento gerenciáveis e obter resultados de forma relativamente rápida.
Estratégias para limitar o tamanho do conjunto de dados de treinamento
Você pode usar estratégias diferentes para reduzir o tamanho do conjunto de dados de treinamento e o tempo de processamento associados sem afetar significativamente a precisão do modelo preditivo resultante.
- No processo de treinamento, exclua campos que não contribuem para a precisão preditiva. Exclua campos irrelevantes e redundantes.
- Se os campos datahora não contribuem para a precisão preditiva, exclua-os do processo de treinamento. No entanto, considere cuidadosamente a relevância dos campos datahora. Para mais informações, consulte Campos-chave datahora.
- Amostre o conjunto de dados de treinamento e use os dados amostrados como entrada para o processo de treinamento Entre as abordagens de amostragem possíveis, estão:
- equilíbrio do tamanho das classes de dados por meio da amostragem de classes majoritárias para aproximar o tamanho médio das classes minoritárias
- amostragem aleatória de todo o conjunto de dados de treinamento
- amostragem estratificada baseada em recursos
- amostragem estratificada baseada em clusterização
Campos-chave datahora
Você pode usar um ou mais campos datahora como campos-chave ao treinar um modelo preditivo. Normalmente, há um número excessivo de valores únicos em um campo datahora, o que impede que ele seja uma fonte adequada de categorias ou recursos identificáveis para o processo de treinamento. Além, disso, os dados datahora brutos podem parecer não relacionados ao campo de destino de interesse.
No entanto, uma vez categorizados, os dados datahora podem ser relevantes. Por exemplo, os eventos examinados podem ter um padrão de ocorrer em determinados dias da semana ou durante certos horários do dia.
O processo de treinamento deriva automaticamente vários recursos sintéticos de cada campo datahora por meio da categorização dos dados datahora brutos. Esses recursos sintéticos são incluídos no algoritmo que gera um modelo preditivo.
Recursos sintéticos derivados de campos datahora
Os recursos sintéticos derivados automaticamente de campos de data, hora ou datahora são listados abaixo.
| Descrição do recurso sintético | Tipo de recurso | Nome do recurso sintético |
|---|---|---|
| Dia da semana | Numérico (1 a 7) | nomecampo_DOW |
| Mês do ano | Numérico (1 a 12) | nomecampo_MONTH |
| Trimestre | Numérico (1 a 4) | nomecampo_QTR |
| Número de dias desde o início do mês | Numérico (1 a 31) | nomecampo_DAY |
| Número de dias desde o início do ano | Numérico (1 a 366) | nomecampo_DOY |
| Segundos | Numérico (0 a 59) | nomecampo_SECOND |
| Hora do dia | Numérico (1 a 24) | nomecampo_HOUR |
| Número de segundos desde o início do dia | Numérico (1 a 86400) | nomecampo_SOD |
| Quartil do dia |
Categóricos:
|
nomecampo_QOD |
| Octil do dia |
Categóricos:
|
nomecampo_OOD |
Treinamento de um modelo preditivo
Observação
O tamanho máximo permitido para o conjunto de dados usados com no processo de treinamento é 1 GB.
Se as opções do menu de aprendizado de máquina estiverem desativadas, é provável que o mecanismo do Python não esteja instalado. Para obter mais informações, consulte Instalar o ACL para Windows.
Etapas
Especifique configurações básicas para o processo de treinamento
- Abra a tabela do Analytics com o conjunto de dados de treinamento.
- No menu principal do Analytics, selecione Aprendizado de máquina > Treinar.
- Especifique o tempo destinado ao processo de treinamento:
Opção Detalhes Tempo para pesquisar um modelo ideal O tempo total em minutos para gerar e testar modelos preditivos e selecionar um modelo vencedor.
Especifique um tempo de pesquisa equivalente a pelo menos 10 vezes o tempo máximo de avaliação por modelo.
Tempo máximo por avaliação de modelo Tempo de execução máximo em minutos por avaliação de modelo.
Reserve 45 minutos para cada 100 MB de dados de treinamento.
Observação
O tempo de execução total do processo de treinamento é o tempo de pesquisa mais até duas vezes o tempo máximo de avaliação de modelo.
O tempo sugerido é um compromisso entre tempo de processamento e a avaliação de vários tipos de modelo.
- Especifique o tipo de previsão a ser usado:
- Classificação Use algoritmos de classificação para treinar um modelo
Use a classificação se quiser prever a que classe ou categoria os registros de um conjunto de dados não rotulado pertencem.
- Regressão Use algoritmos de regressão para treinar um modelo
Use regressão se quiser prever valores numéricos associados aos registros em um conjunto de dados não rotulado.
Para informações sobre os algoritmos específicos usados com classificação e regressão, consulte Algoritmos de treinamento.
- Classificação Use algoritmos de classificação para treinar um modelo
- Na lista suspensa Pontuador do modelo, selecione a métrica a ser usada para pontuar os modelos gerados durante o processo de treinamento.
O modelo gerado com o melhor valor para essa métrica é mantido e os demais são descartados.
Um subconjunto diferente de métricas está disponível dependendo do tipo de previsão que você está usando:
Tipo de previsão Métricas disponíveis Classificação Perda de log | AUC | Precisão | F1 | Precisão | Recall Regressão Erro quadrático médio | Erro absoluto médio | R2 Observação
A métrica de classificação AUC somente é válida quando usada em um campo de destino que contém dados binários, ou seja, duas classes, como Sim/Não ou Verdadeiro/Falso.
Selecionar campos
- Na lista Treinar com base em, selecione um ou mais campos-chave para usar como entrada no treinamento do modelo.
Os campos-chave são os recursos que formam a base para a previsão de valores de campos de destino em um conjunto de dados não rotulado. Os campos-chave podem ser de caracteres, numéricos, datahora ou lógicos. Os recursos sintéticos são derivados automaticamente de campos-chave datahora.
Observação
Os campos de caracteres devem ser "categóricos". Ou seja, devem identificar categorias ou classes e não podem exceder um número máximo de valores únicos.
O máximo é especificado pela opção Máximo das categorias (Ferramentas > Opções > Comando).
Dica
Você pode usar Shift+clique para selecionar vários cabeçalhos de colunas adjacentes e Ctrl+clique para selecionar vários cabeçalhos de colunas adjacentes.
- Na lista Campo de destino, selecione o campo de destino.
O campo de destino é o campo que o modelo é treinado para prever com base nos campos-chave de entrada.
A classificação e a regressão funcionam com tipos de dados de campos de destino diferentes:
- classificação um campo de destino de caracteres ou lógico
- regressão um campo de destino numérico
Atribua um nome ao arquivo de modelo e à tabela do Analytics de saída
- Na caixa de texto Nome do modelo, especifique o nome do arquivo de modelo gerado pelo processo de treinamento.
O arquivo de modelo contém o modelo mais adequado ao conjunto de dados de treinamento. Você informará o arquivo de modelo ao processo de previsão para gerar previsões sobre um conjunto de dados novo e desconhecido.
- Na caixa de texto Para, especifique o nome da tabela de avaliação de modelo gerada pelo processo de treinamento.
A tabela de avaliação de modelos contém dois tipos distintos de informações:
- Pontuador/métrica para a classificação ou as métricas de regressão, estimativas quantitativas do desempenho preditivo do arquivo de modelo gerado pelo processo de treinamento
- Importância/coeficiente em ordem decrescente, valores que indicam quanto cada recurso (previsor) contribui para as previsões efetuadas pelo modelo
Observação
Os nomes de tabela do Analytics são limitados a 64 caracteres alfanuméricos, sem contar a extensão .FIL. O nome pode incluir o caractere de sublinhado ( _ ) mas nenhum outro caractere especial e nenhum espaço. O nome não pode começar com um número.
-
Se existirem registros na exibição atual que você desejar excluir do processamento, insira uma condição na caixa de texto Se ou clique em Se para criar uma instrução IF usando o Construtor de expressões.
Observação
A condição Se é avaliada apenas em relação aos registros restantes em uma tabela depois da aplicação das opções de escopo (Primeiros, Próximos, Enquanto).
A instrução IF considera todos os registros na exibição e filtra aqueles que não atendem à condição especificada.
Especifique que somente um subconjunto dos dados de treinamentos seja usado (opcional)
Na guia Mais, selecione uma das opções no painel Escopo:
| Opção de escopo | Detalhes |
|---|---|
| Todas | (Padrão) Especifica que todos os registros na tabela são processados. |
| Primeiro |
Insira um número na caixa de texto. Começa o processamento no primeiro registro da tabela e inclui apenas o número especificado de registros. |
| Próxima |
Selecione essa opção e insira um número na caixa de texto para começar a processar no registro selecionado no momento na exibição da tabela e incluir somente o número especificado de registros. Insira um número na caixa de texto. Começa o processamento no registro atualmente selecionado da exibição da tabela e inclui apenas o número especificado de registros. Na coluna mais à esquerda na exibição, deve ser selecionado o número real de registros, não os dados na linha. |
| Enquanto |
Use uma instrução WHILE para limitar o processamento de registros na tabela com base em um critério específico ou conjunto de critérios. Insira uma condição na caixa de texto Enquanto ou clique em Enquanto para criar uma instrução WHILE usando o Construtor de Expressões. Uma instrução WHILE permite que os registros na exibição sejam processados somente enquanto a condição especificada avaliar como verdadeiro. Assim que a condição avaliar como falso, o processamento será encerrado e nenhum outro registro será considerado. A opção Enquanto pode ser usada em conjunto com as opções Todos, Primeiro e Próximos. O processamento de registros será interrompido assim que um limite for alcançado. |
Especifique configurações avançadas para o processo de treinamento
- Na guia Mais, especifique o Número de partições de validação cruzada.
Deixe o número padrão de 5 ou especifique um número diferente. Os números válidos são de 2 a 10.
As partições são subdivisões do conjunto de dados de treinamento e são usadas em um processo de validação cruzada durante a avaliação e otimização do modelo.
Normalmente, o uso de 5 a 10 partições gera bons resultados no treinamento de um modelo.
Dica
O aumento do número de partições pode gerar uma estimativa melhor do desempenho preditivo de um modelo, mas também aumenta o tempo de execução geral.
- Opcional. Selecione Origem e insira um número.
O valor de origem é usado para inicializar o gerador de números aleatórios no Analytics.
Se você não selecionar Origem, o Analytics selecionará aleatoriamente o valor de origem.
Especifique explicitamente um valor de origem, e o registre, se quiser replicar o processo de treinamento com o mesmo conjunto de dados no futuro.
- Opcional. Se você quiser treinar e pontuar apenas modelos lineares, selecione Avaliar apenas modelos lineares.
Se você não selecionar essa opção, todos os tipos de modelo relevantes à classificação ou à regressão serão avaliados.
Observação
Com conjuntos de dados maiores, o processo de treinamento normalmente é concluído em menos tempo se você inclui apenas modelos lineares.
A inclusão de modelos lineares garante coeficientes na saída.
- Opcional. Selecione Desativar seleção e pré-processamento de recursos se quiser excluir esses subprocessos do processo de treinamento.
A seleção de recursos é a seleção automatizada de campos no conjunto de dados de treinamento que são os mais úteis na otimização do modelo preditivo. A seleção automatizada pode aprimorar o desempenho preditivo e reduzir a quantidade de dados envolvidos na otimização do modelo.
O pré-processamento de dados executa transformações como alteração de escala e padronização do conjunto de dados de treinamento para aumentar sua adequação aos algoritmos de treinamento.
Cuidado
Você deve desativar a seleção de recursos e o pré-processamento de dados somente se tiver um motivo para isso.
- Clique em OK.
O processo de treinamento é iniciado e uma caixa de diálogo é exibida, mostrando as configurações de entrada especificadas e o tempo de processamento decorrido.
Aplicação de um modelo preditivo a um conjunto de dados não rotulado
Observação
Se as opções do menu de aprendizado de máquina estiverem desativadas, é provável que o mecanismo do Python não esteja instalado. Para obter mais informações, consulte Instalar o ACL para Windows.
Etapas
- Abra a tabela do Analytics com o conjunto de dados não rotulado.
- No menu principal do Analytics, selecione Aprendizado de máquina > Prever.
- Clique em Modelo e, na caixa de diálogo Selecionar arquivo, selecione um arquivo de modelo gerado por um processo de treinamento anterior e clique em Abrir.
Os arquivos de modelos têm uma extensão de arquivo *.model.
Observação
O arquivo de modelo deve ter sido treinado em um conjunto de dados com os mesmos arquivos que o conjunto de dados não rotulado, ou substancialmente os mesmos arquivos.
Não é possível usar um arquivo de modelo treinado na versão 14.1 do Analytics. Os arquivos do modelo da versão 14.1 não são compatíveis com as versões subsequentes do Analytics. Treine um novo modelo preditivo para uso com o processo de previsão.
- Na caixa de texto Para, especifique o nome da tabela do Analytics gerada pelo processo de previsão.
A tabela de saída contém os campos-chave especificados durante o processo de treinamento e um ou dois campos gerados pelo processo de previsão:
- Previsto as classes ou valores numéricos previstos associados a cada registro em um conjunto de dados não rotulado
- Probabilidade (somente classificação) a probabilidade de que uma classe prevista é precisa
Observação
Os nomes de tabela do Analytics são limitados a 64 caracteres alfanuméricos, sem contar a extensão .FIL. O nome pode incluir o caractere de sublinhado ( _ ) mas nenhum outro caractere especial e nenhum espaço. O nome não pode começar com um número.
-
Se existirem registros na exibição atual que você desejar excluir do processamento, insira uma condição na caixa de texto Se ou clique em Se para criar uma instrução IF usando o Construtor de expressões.
Observação
A condição Se é avaliada apenas em relação aos registros restantes em uma tabela depois da aplicação das opções de escopo (Primeiros, Próximos, Enquanto).
A instrução IF considera todos os registros na exibição e filtra aqueles que não atendem à condição especificada.
- Opcional. Para processar apenas um subconjunto do conjunto de dados não rotulado, na guia Mais, selecione uma das opções no painel Escopo:
- Clique em OK.
Algoritmos de treinamento
Três comandos de treinamento determinam quais algoritmos de aprendizado de máquina são usados para treinar um modelo preditivo:
| Opção | Guia da caixa de diálogo Treinar |
|---|---|
| Classificação ou Regressão | Guia Principal |
| Avaliar apenas modelos lineares | Guia Mais |
| Desativar seleção e pré-processamento de recursos | Guia Mais |
As seções a seguir resumem como as opções controlam quais algoritmos são usados.
Os nomes dos algoritmos não são exibidos na interface do usuário do Analytics. O nome do algoritmo selecionado pelo comando de treinamento para gerar o modelo é exibido no log.
Observação
Para obter informações detalhadas sobre os algoritmos, consulte a documentação do scikit-learn. Scikit-learn é a biblioteca de aprendizado de máquina em Python usada pelo Analytics.
Algoritmos de classificação
![]() Algoritmo usado
Algoritmo usado ![]() Algoritmo não usado
Algoritmo não usado
| Nome do algoritmo | Sempre incluído | Avaliar apenas modelos lineares | Desativar seleção e pré-processamento de recursos | ||
|---|---|---|---|---|---|
| Opção não selecionada (padrão) | Opção selecionada | Opção não selecionada (padrão) | Opção selecionada | ||
| Tipo de algoritmo: Classificador (Classifier) | |||||
| Regressão logística (Logistic Regression) |
|
||||
| Máquina de vetores de suporte linear (Linear Support Vector Machine) |
|
||||
| Floresta aleatória (Random Forest) |
|
|
|||
| Árvores extremamente aleatórias (Extremely Randomized Trees) |
|
|
|||
| Máquina de reforço de gradientes (Gradient Boosting Machine) |
|
|
|||
| Tipo de algoritmo: Pré-processador de recursos (Feature preprocessor) | |||||
| Codificação one hot – de recursos de categorização |
|
||||
| Análise rápida de componentes independentes (Fast Independent Component Analysis) |
|
|
|||
| Aglomeração de recursos (Feature agglomeration) |
|
|
|||
| Análise de componentes principais – Decomposição de valor singular |
|
|
|||
| Recursos polinomiais de segundo grau (Second Degree Polynomial Features) |
|
|
|||
| Binarizador (Binarizer) |
|
|
|||
| Dimensionador robusto (Robust Scaler) |
|
|
|||
| Dimensionador padrão (Standard Scaler) |
|
|
|||
| Dimensionador de máximo absoluto (Maximum Absolute Scaler) |
|
|
|||
| Dimensionador de mínimo e máximo (Min Max Scaler) |
|
|
|||
| Normalizador (Normalizer) |
|
|
|||
| Aproximação de kernel de Nystroem (Nystroem Kernel Approximation) |
|
|
|||
| Aproximação de kernel de RBF (RBF Kernel Approximation) |
|
|
|||
| Contador de zeros (Zero Counter) |
|
|
|||
| Tipo de algoritmo: Seletor de recursos (Feature selector) | |||||
| Taxa de erros da família (Family-wise Error Rate) |
|
|
|||
| Percentil de pontuações mais altas (Percentile of Highest Scores) |
|
|
|||
| Limite de variação (Variance Threshold) |
|
|
|||
| Eliminação de recursos recursivos (Recursive Feature Elimination) |
|
|
|||
| Ponderação de importância (Importance Weights) |
|
|
|||
Algoritmos de regressão
![]() Algoritmo usado
Algoritmo usado ![]() Algoritmo não usado
Algoritmo não usado
| Nome do algoritmo | Sempre incluído | Avaliar apenas modelos lineares | Desativar seleção e pré-processamento de recursos | ||
|---|---|---|---|---|---|
| Opção não selecionada (padrão) | Opção selecionada | Opção não selecionada (padrão) | Opção selecionada | ||
| Tipo de algoritmo: Regressor | |||||
| Rede elástica (Elastic Net) |
|
||||
| Laço (Lasso) |
|
||||
| Crista (Ridge) |
|
||||
| Máquina de vetores de suporte linear (Linear Support Vector Machine) |
|
||||
| Floresta aleatória (Random Forest) |
|
|
|||
| Árvores extremamente aleatórias (Extremely Randomized Trees) |
|
|
|||
| Máquina de reforço de gradientes (Gradient Boosting Machine) |
|
|
|||
| Tipo de algoritmo: Pré-processador de recursos (Feature preprocessor) | |||||
| Codificação one hot – de recursos de categorização |
|
||||
| Análise rápida de componentes independentes (Fast Independent Component Analysis) |
|
|
|||
| Aglomeração de recursos (Feature agglomeration) |
|
|
|||
| Análise de componentes principais – Decomposição de valor singular |
|
|
|||
| Recursos polinomiais de segundo grau (Second Degree Polynomial Features) |
|
|
|||
| Binarizador (Binarizer) |
|
|
|||
| Dimensionador robusto (Robust Scaler) |
|
|
|||
| Dimensionador padrão (Standard Scaler) |
|
|
|||
| Dimensionador de máximo absoluto (Maximum Absolute Scaler) |
|
|
|||
| Dimensionador de mínimo e máximo (Min Max Scaler) |
|
|
|||
| Normalizador (Normalizer) |
|
|
|||
| Aproximação de kernel de Nystroem (Nystroem Kernel Approximation) |
|
|
|||
| Aproximação de kernel de RBF (RBF Kernel Approximation) |
|
|
|||
| Contador de zeros (Zero Counter) |
|
|
|||
| Tipo de algoritmo: Seletor de recursos (Feature selector) | |||||
| Taxa de erros da família (Family-wise Error Rate) |
|
|
|||
| Percentil de pontuações mais altas (Percentile of Highest Scores) |
|
|
|||
| Limite de variação (Variance Threshold) |
|
|
|||
| Ponderação de importância (Importance Weights) |
|
|
|||