Informações do conceito
Uma associação parcial do Analytics usa a correspondência parcial de valores de campos-chave para combinar duas tabelas do Analytics em uma terceira tabela. Em muitos aspectos, uma associação parcial é como uma associação normal do Analytics (consulte Associar tabelas). A principal diferença é que, além de associar registros de acordo com a correspondência exata de valores de campos-chave, a associação parcial pode associar registros de acordo com correspondências aproximadas.
A associação parcial é útil quando chaves primárias e secundárias contém o mesmo tipo de dados, mas em formato ligeiramente diferente. Ou quando os dados nas chaves têm ligeiras irregularidades, como erros digitação, que evitam uma correspondência exata.
Exemplo
Cenário
Você deseja identificar qualquer fornecedor que também seja funcionário como um modo de analisar dados para possíveis pagamentos inadequados.
Abordagem
Você associa a tabela mestre de fornecedores com a tabela de funcionários, usando o campo de endereço em cada tabela como chave comum (Rua_Fornecedor e Endereço_Emp). No entanto, o formato dos dados de endereço nos campos-chave varia ligeiramente. Portanto, você usa uma associação parcial em vez de uma associação normal.
Exame de alguns dados
Sem um trabalho considerável de limpeza e harmonização de dados, os valores-chave primários e secundários mostrados abaixo não seriam associados em uma associação normal do Analytics, embora sejam muito provavelmente endereços correspondentes.
| Valores-chave primários | Valores-chave secundários |
|---|---|
| 605 3rd Avenue | 605 Third Avenue |
| 400 High St SE | 400 High Street S.E. |
| 2203 Rowan Street | 2203 Rowen St |
Mesmo após uma limpeza e harmonização de dados, valores-chave com pequenas diferenças ortográficas, como "Rowan" e "Rowen", provavelmente não seriam correspondidos.
Os valores-chave poderiam ser associados em uma associação parcial, dependendo das configurações dessa associação parcial.
Resultados de saída
No exemplo de tabela associada abaixo, as correspondências exatas de valores-chave estão realçadas em roxo e as correspondências parciais de valores-chave estão realçadas em verde.
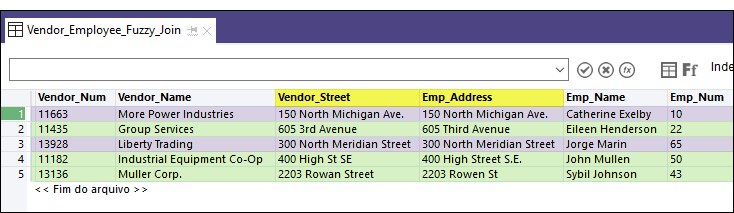
Associação parcial versus duplicidades parciais
Uma associação parcial analisa valores em campos-chave de duas tabelas. Para testar a existência de valores praticamente idênticos em uma única tabela do Analytics, consulte Análise de duplicidades parciais.
Aumento da eficácia da associação parcial
Você pode aprimorar significativamente a eficácia da associação parcial incorporando uma ou mais das seguintes técnicas:
- ordenar elementos individuais em valores de campos-chave primários e secundários
- remoção de elementos genéricos dos valores de campos-chave primários e secundários
- harmonização de valores de campos-chave primários e secundários
Essas técnicas permitem usar configurações de parcialidade mais restritas e ainda obter as mesmas correspondências parciais, mas reduzindo o número de falsos positivos. Você pode usar as técnicas separadamente ou combinadas.
Criar uma expressão ou um campo calculado
Para usar uma das técnicas, você precisa criar uma expressão ou campo calculado usando a função do Analytics adequada e um ou ambos os campos-chave.
Para obter mais informações sobre expressões, consulte Usar expressões.
Para obter mais informações sobre campos calculados, consulte Definir campos calculados.
Observação
A caixa de diálogo Associação parcial não permite criar uma expressão em um campo-chave secundário. No entanto, você pode criar manualmente uma expressão de campo-chave secundário na linha de comando do Analytics ou em um script. Outra opção é criar um campo calculado para uso como campo-chave secundário.
Ordenação de elementos individuais em valores de campos-chave
A função SORTWORDS( ) pode aumentar a eficácia da associação parcial ordenando sequencialmente elementos individuais em valores de campos-chave primários e secundários.
A ordenação de elementos, como os componentes de um endereço, pode fazer com que valores de campos-chave com as mesmas informações, mas em formatos diferentes, sejam mais semelhantes entre si. Uma maior semelhança aumenta a probabilidade de que valores de campos-chave sejam selecionados como correspondências parciais entre si.
Para obter mais informações, consulte Função SORTWORDS( ).
Para ver um vídeo com uma visão geral de SORTWORDS( ), consulte Correspondência parcial usando SORTWORDS() (somente em inglês).
Observação
A ordenação de elementos em valores de campos-chave é mais adequada para associações parciais usando o algoritmo de distância de Levenshtein.
A ordenação de elementos com associação parcial usando o algoritmo do coeficiente de Dice pode ou não ser benéfica. Teste um conjunto de dados de amostra antes de decidir usar SORTWORDS( ) com o algoritmo do coeficiente de Dice em um ambiente de produção.
Cuidado
Se você usar SORTWORDS( ) com uma associação parcial, deverá aplicar SORTWORDS( ) em ambas as cadeias ou campos sendo comparados.
Remoção de elementos genéricos dos valores de campos-chave
A função OMIT( ) pode melhorar a eficácia da associação parcial removendo elementos genéricos, como "Companhia" ou "Inc.", ou caracteres como vírgulas, pontos e E comercial (&), dos valores dos campos-chave primários e secundários.
A remoção de elementos e pontuação genéricos concentra a associação parcial na parte dos valores de campos-chave em que podem ocorrer diferenças significativas.
Para obter mais informações, consulte Função OMIT( ).
Harmonização de valores de campo-chave
As funções REPLACE( ) ou REGEXREPLACE( ) podem aprimorar a eficácia da associação parcial harmonizando formas variáveis do mesmo elemento em valores de campos-chave primários e secundários. Por exemplo, você pode harmonizar "Rua", "R." e "R" para usar o único valor "R".
A harmonização de elementos pode fazer com que valores de campos-chave com as mesmas informações, mas em formatos diferentes, sejam mais semelhantes entre si. Uma maior semelhança aumenta a probabilidade de que valores de campos-chave sejam selecionados como correspondências parciais entre si.
Para obter mais informações, consulte Função REPLACE( ) para substituições simples e Função REGEXREPLACE( ) para substituições mais complexas.
Tamanho da tabela de saída e desempenho dos comandos
Tamanho da tabela de saída
A associação parcial é semelhante à associação de muitos para muitos do Analytics. Todos os valores-chave primários podem ser correspondidos a todos os valores-chave secundários. O tamanho da tabela de saída pode ser muitas vezes maior que o tamanho das tabelas de entrada primária e secundária.
Desempenho dos comandos
Os algoritmos de correspondência parcial garantem que apenas valores-chave com um grau de parcialidade especificado, ou valores com correspondência exata, sejam realmente associados. No entanto, todas as possíveis correspondências primária-secundária devem ser testadas, o que significa que o processo de associação parcial pode ser demorado. O número de testes individuais que deve ser executado é igual ao número de registros na tabela primária multiplicado pelo número de registros na tabela secundária.
Limitar a correspondência à primeira correspondência secundária
Você pode reduzir consideravelmente o tempo de processamento e o tamanho dos resultados de saída selecionando Associar apenas a primeira ocorrência de chave secundária correspondente. A ativação desta opção especifica que cada valor de chave primária é associado unicamente à primeira ocorrência de qualquer valor de chave secundária correspondente.
A ativação da opção é adequada nestas situações:
- Alguma correspondência? você quer apenas saber se existem correspondências, exatas ou parciais, entre as duas tabelas e desejar evitar o tempo de processamento necessário para identificar todas as correspondências
- Pelo menos uma correspondência você tem certeza de que existe no máximo apenas uma correspondência na tabela secundária para cada valor de chave primária
A habilitação dessa opção não é apropriada quando você precisa gerar resultados que contêm todas as associações possíveis entre valores das chaves primária e secundárias.
Observação
Se você selecionar Associar apenas a primeira ocorrência de chave secundária correspondente e a primeira ocorrência for uma correspondência exata, todas as correspondências parciais subsequentes para o valor de chave primária serão incluídas na tabela de saída associada.
Práticas recomendadas
Considere o tamanho da tabela de saída e o desempenho dos comandos ao preparar tabelas de entrada primárias e secundárias e especifique o grau de parcialidade.
- Personalize os dados Garanta que apenas os registros relevantes sejam incluídos nas tabelas primária e secundária. Se você sabe que alguns registros não serão correspondidos, filtre esses registros para eliminá-los antes da execução da correspondência parcial.
- Execuções de teste Para conjuntos de dados grandes, execute testes em uma pequena parte dos dados como uma forma mais eficiente de determinar configurações adequadas para os algoritmos de correspondência parcial. Comece com configurações de parcialidade mais conservadoras e, se necessário, relaxe progressivamente as configurações.
Algoritmos de correspondência parcial
Quando você executa uma associação parcial, opta entre dois algoritmos de correspondência parcial diferentes:
- Coeficiente de Dice
- Distância de Levenshtein
Os algoritmos operam de forma completamente independente entre si e podem gerar resultados um pouco diferentes. Uma abordagem é executar a associação parcial duas vezes, uma com cada algoritmo, e comparar os resultados. Normalmente, várias correspondências parciais em cada conjunto de resultados se sobrepõem, mas algumas correspondências podem ser únicas em cada conjunto de resultados.
Grau de parcialidade
Você especifica o grau de parcialidade para cada algoritmo, o que pode alterar drasticamente o tamanho e a composição do conjunto de resultados. O "grau de parcialidade" indica o quanto dois valores correspondem.
Dependendo do algoritmo selecionado, você usa as seguintes configurações para controlar o grau de parcialidade:
| Algoritmo | Configuração |
|---|---|
|
Coeficiente de Dice |
|
|
Distância de Levenshtein |
|
Experimente graus de parcialidade diferentes. Comece com valores conservadores e gere conjuntos de resultados menores e relaxe progressivamente as configurações até começar a obter um número excessivo de valores associados que são obviamente não correspondentes (falsos positivos).
Coeficiente de Dice
O algoritmo do coeficiente de Dice opera medindo o grau de similaridade entre um valor-chave primário e secundário, em uma escala de 0,0000 a 1,0000. Quanto maior o coeficiente de Dice dos dois valores, maior a semelhança desses valores.
| Coeficiente de Dice | Significado |
|---|---|
| 1,0000 |
Cada valor é composto por conjunto de caracteres idêntico, embora os caracteres possam estar em ordem diferente ou serem caracteres maiúsculos em um conjunto de caracteres e caracteres minúsculos no outro conjunto de caracteres. Os ngramas nos dois valores são 100% idênticos. Os ngramas são explicados abaixo. |
| 0,7500 |
Os ngramas nos dois valores são 75% idênticos. |
| 0,0000 | Os dois valores não têm ngramas idênticos ou o comprimento especificado na configuração do ngrama é maior que o menor dos dois valores comparados. |
Ngramas
O coeficiente de Dice é calculado dividindo antes os valores sendo comparadas em ngramas. Os ngramas estão sobrepondo blocos de caracteres, com um comprimento de n, que é o comprimento especificado na configuração do ngrama.
Veja a seguir dois dos valores do exemplo acima, divididos em ngramas com um comprimento de 2 caracteres (n = 2).
| Valor | Ngramas |
|---|---|
| 2203 Rowan Street | 22 | 20 | 03 | 3_ | _R | Ro | ow | wa | an | n_ | _S | St | tr | re | ee | et |
| 2203 Rowen St | 22 | 20 | 03 | 3_ | _R | Ro | ow | we | en | n_ | _S | St |
O coeficiente de Dice é a porcentagem dos ngramas idênticos nos dois valores. Neste caso, 20 dos 28 ngramas são idênticos, o que corresponde a 71,43%, ou 0,7143 como fração decimal.
Observação
O aumento do comprimento da configuração do ngrama aumenta o rigor do critério de similaridade entre os dois valores.
Porcentagem
Quando você especifica uma configuração Porcentagem, define o menor coeficiente de Dice permitido de dois valores para que eles sejam qualificados como uma correspondência parcial. Por exemplo, se você especificar 0.7500 pelo menos 75% dos ngramas nos dois valores devem ser idênticos para criar uma correspondência.
| Configuração de porcentagem | Significado | 2203 Rowan Street / 2203 Rowen St |
|---|---|---|
| 0,7500 |
Para qualificação como correspondência parcial, pelo menos 75% dos ngramas nos dois valores devem ser idênticos. |
Não correspondentes, não incluídos na tabela associada (coeficiente de Dice = 0,7143) |
| 0,7000 |
Para qualificação como correspondência parcial, pelo menos 70% dos ngramas nos dois valores devem ser idênticos. |
Correspondentes, incluídos na tabela associada (coeficiente de Dice = 0,7143) |
Para obter informações detalhadas sobre o funcionamento do coeficiente de Dice, consulte a Função DICECOEFFICIENT( ).
Distância de Levenshtein
O algoritmo da distância de Levenshtein opera medindo o grau de diferença entre um valor-chave primário e secundário, em uma escala de números inteiros iniciada em 0. A escala representa o número de edições de único caractere necessárias para tornar um valor idêntico ao outro. Quanto maior a distância de Levenshtein entre os dois valores, maior a diferença entre eles.
| Distância de Levenshtein | Significado |
|---|---|
| 3 | Cada valor é composto por conjunto de caracteres idêntico, em ordem idêntica. Maiúsculas e minúsculas podem variar. |
| 2 |
Duas edições de um único caractere são necessárias para tornar os dois valores idênticos. Por exemplo: "Smith" e "Smythe"
|
| 3 |
Três edições de um único caractere são necessárias para tornar os dois valores idênticos. Por exemplo: "Hanssen" e "Jansn"
|
Distância
Quando você especifica uma configuração Distância, define a máxima distância de Levenshtein permitida entre dois valores para que eles sejam qualificados como uma correspondência parcial. Por exemplo, se você especificar 2, no máximo duas edições poderão ser necessárias para tornar os dois valores idênticos.
| Configuração de distância | Significado | Hanssen / Jansn |
|---|---|---|
| 2 |
Para qualificação como correspondência parcial, no máximo duas edições de caractere poderão ser necessárias para tornar os dois valores idênticos. |
Não correspondentes, não incluídos na tabela associada (Distância de Levenshtein = 3) |
| 3 |
Para qualificação como correspondência parcial, no máximo três edições de caractere poderão ser necessárias para tornar os dois valores idênticos. |
Correspondentes, incluídos na tabela associada (Distância de Levenshtein = 3) |
Para obter informações detalhadas sobre o funcionamento da distância de Levenshtein, consulte a Função LEVDIST( ). Ao contrário da função, o algoritmo de distância de Levenshtein usado na associação parcial remove automaticamente brancos à esquerda e à direita e não diferencia maiúsculas de minúsculas.
Etapas
Você pode usar a correspondência parcial de valores de campos-chave para combinar duas tabelas do Analytics em uma terceira tabela.
Observação
Informações detalhadas são exibidas após as etapas. Consulte Opções da caixa de diálogo Associação parcial.
- No Navegador, abra a tabela primária, clique com o botão direito do mouse na tabela secundária e selecione Abrir como secundária.
Os ícones das tabelas primária e secundária são atualizados com os números 1 e 2 para indicar o relacionamento entre elas

 .
. - Selecione Dados > Associação parcial.
- Na guia Principal, selecione o algoritmo de correspondência parcial a ser usado:
- Coeficiente de Dice
- Levenshtein
- Dependendo do algoritmo selecionado, informe as configurações para controlar o grau de parcialidade.
Coeficiente de Dice
- Ngrama
- Porcentagem
Levenshtein
- Distância
As configurações são explicadas abaixo.
- (Opcional) Selecione Associar apenas a primeira ocorrência de chave secundária correspondente para especificar que cada valor de chave primária é associado unicamente à primeira ocorrência de quaisquer valores de chaves secundárias correspondentes.
- Selecione o campo-chave primário da lista Chaves primárias.
Você pode selecionar apenas um campo-chave primário, que deve ser um campo de caracteres.
- Selecione o campo-chave secundário da lista Chaves secundárias.
Você pode selecionar apenas um campo-chave secundário, que deve ser um campo de caracteres.
- Selecione os campos a serem incluídos na tabela associada das listas Campos primários e Campos secundários.
Observação
Você deve selecionar de forma explícita os campos-chave primário e secundário se desejar inclui-los na tabela associada.
Dica
Você pode usar Shift+clique para selecionar vários cabeçalhos de colunas adjacentes e Ctrl+clique para selecionar vários cabeçalhos de colunas adjacentes.
- Na caixa de texto Para, especifique o nome da nova tabela associada.
- (Opcional) Na guia Mais:
- Se você quiser processar apenas um subconjunto de registros, selecione uma das opções no painel Escopo.
- Se você quiser anexar (adicionar) os resultados de saída ao final de uma tabela do Analytics existente, selecione Anexar a um arquivo existente.
- Clique em OK.
A nova tabela associada é gerada.
Opções da caixa de diálogo Associação parcial
As tabelas abaixo fornecem informações detalhadas sobre as opções da caixa de diálogo Associação parcial.
Guia Principal
| Opções – Caixa de diálogo Associação parcial | Descrição |
|---|---|
| Coeficiente de Dice |
Use o coeficiente de Dice para correspondência parcial entre valores-chave primários e secundários.
|
| Levenshtein |
Use a distância de Levenshtein para correspondência parcial entre valores-chave primários e secundários.
|
| Associar apenas a primeira ocorrência de chave secundária correspondente |
Especifica que cada valor de chave primária é associado unicamente à primeira ocorrência de qualquer chave secundária correspondente. Se você deixar a opção desmarcada, o comportamento padrão será associar cada valor de chave primária a todas as ocorrências de todas as chaves secundárias correspondentes. |
| Tabela secundária | Um método alternativo para selecionar a tabela secundária. |
| Chaves primárias Chaves secundárias |
Especifica o campo-chave comum a ser usado para associar as duas tabelas.
Diretrizes para campos-chave:
|
| Campos primários Campos secundários |
Especifica os campos a serem incluídos na tabela associada.
|
| Usar tabela de saída | Especifica que a tabela do Analytics contendo os resultados de saída deve ser aberta automaticamente ao completar a operação. |
| Se |
(Opcional) Permite criar uma condição para excluir registros do processamento.
|
| Para | Especifique o nome e o local da tabela resultante.
Independentemente de onde a tabela resultante for salva, ela será adicionada ao projeto aberto caso ainda não esteja no projeto. Se o Analytics preencher um nome de tabela, você poderá aceitar o nome preenchido ou alterá-lo. Observação Os nomes de tabela do Analytics são limitados a 64 caracteres alfanuméricos, sem contar a extensão .FIL. O nome pode incluir o caractere de sublinhado ( _ ) mas nenhum outro caractere especial e nenhum espaço. O nome não pode começar com um número. |
Guia Mais
| Opções – Caixa de diálogo Associação parcial | Descrição |
|---|---|
| Painel Escopo | Especifica quais registros da tabela primária são processados:
Observação O número de registros especificados nas opções Primeiros ou Próximos faz referência à ordem física ou indexada de registros em uma tabela e desconsidera qualquer filtro ou ordenação rápida aplicada na exibição. Entretanto, resultados de operações analíticas respeitam qualquer filtro. Se uma exibição for ordenada rapidamente, Próximos se comporta como Primeiros. |
| Anexar a um arquivo existente | Especifica que os resultados sejam anexados (adicionados) ao final de uma tabela existente do Analytics. Observação É recomendado deixar a opção Anexar a um arquivo existente desmarcada caso você não esteja certo de que os resultados de saída e a tabela existente tenham a mesma estrutura de dados. Para obter mais informações sobre anexo e estrutura de dados, consulte Anexação de resultados de saída a uma tabela existente. |
| OK | Executa a operação.
|