Duplicidades parciais são valores de caracteres quase idênticos que podem se referir à mesma entidade real. Por exemplo, os quatro valores a seguir podem ser a mesma empresa:
- Intercity Couriers
- Inter-city Couriers
- Intercity Couriers Inc.
- Intrecity Couriers
Causas comuns de duplicidades parciais são erros na entrada de dados, como erros de digitação e ortográficos, diferentes métodos de formatação de dados e de convenções de entrada de dados. A criação intencional de valores quase idênticos podem indicar uma fraude. Duplicidades parciais impedem a análise dos dados, que depende de dados que referenciem entidades reais de maneira consistente.
Duplicidades parciais versus associação parcial
O recurso de duplicidades parciais analisa valores em um único campo de uma única tabela do Analytics. Para usar correspondência parcial para combinar campos de duas tabelas do Analytics em uma terceira nova tabela, consulte Associação parcial.
Como funciona
O recurso de duplicidades parciais do Analytics permite testar um campo de caracteres específico em uma tabela para identificar todas as duplicidades parciais contidas no campo. Os resultados de saída agrupam duplicidades parciais com base em um grau de diferença especificado. Ao ajustar o grau de diferença, você pode controlar o número e o tamanho dos grupos de saída e o valor da diferença entre membros do grupo.
Para confirmar se membros do grupo de duplicidades parciais realmente fazem referência à mesma entidade do mundo real, pode ser necessário executar mais análises, como um teste de duplicidades de campos que não são o campo de teste.
Observação
O teste de duplicidades parciais vai além da identificação de duplicidades exatas. Compreender as configurações que controlam o grau de diferença entre duplicidades parciais e como as duplicidades parciais são agrupadas nos resultados de saída otimizará o uso do recurso.
Resultados de saída de duplicidades parciais
O exemplo abaixo mostra os resultados produzidos pelo teste de duplicidades parciais no campo Sobrenome de uma tabela.
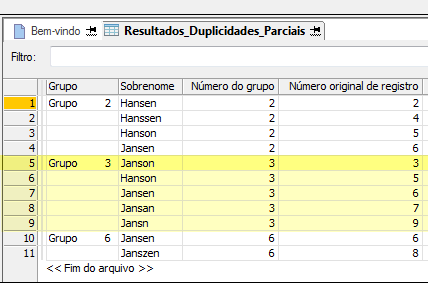
Os resultados de saída são organizados em grupos identificados como 2, 3 e 6. O Número original de registro da primeira duplicidade parcial em cada grupo é usado para identificar o grupo. Por exemplo, "Janson" é o nome no registro número 3 na tabela original, e como "Janson" é o primeiro valor no grupo, com base na sequência de registros da tabela original, o grupo é identificado como Grupo 3. Para obter mais informações, consulte Como as duplicidades parciais são agrupadas.
O recurso de duplicidades parciais usa a comparação baseada em caracteres
Ao combinar dois valores, o recurso de duplicidades parciais executa uma comparação baseada em caracteres, não em palavras. O recurso trata vazios e espaços entra as palavras como caracteres e não diferencia entre palavras individuais. Independentemente do número de palavras individuais em um valor, o recurso trata o valor como uma cadeia de caracteres única e sem quebra.
A implicação dessa abordagem é que alguns valores que parecem ser duplicidades parciais para o olhar humano podem não ser incluídas nos resultados de saída, com base na natureza dos dados e nas configurações de diferenciação especificadas na caixa de diálogo Duplicidades parciais.
Exemplo
Considere estes nomes:
- "JW Smith" e "John William Smith"
- “Diamond Tire” e “Diamond Tire & Auto”
O primeiro exemplo poderia ser duas versões do mesmo nome, uma usando iniciais e outra usando o nome e o nome do meio completos. O segundo exemplo poderia ser uma versão abreviada e uma versão extensa do nome de uma empresa.
Nenhum desses pares de nomes aparecerá como duplicidades parciais, a menos que as configurações de diferenciação sejam definidas com muita liberdade, o que teria o efeito adverso de também retornar um grande número de falsos positivos.
O recurso de duplicidades parciais processa cada par de nomes simplesmente como duas cadeias de caracteres. Em cada caso, como as duas cadeias diferem significativamente em comprimento, as cadeias são significativamente diferentes entre si considerando-se o nível de caracteres.
Para obter mais informações, consulte Como as configurações diferenciais funcionam.
Aumento da eficácia da análise da duplicidade parcial
Além de usar o recurso principal de duplicidades parciais, pode ser necessário limitar o tamanho do conjunto de dados de teste, usar funções auxiliares de duplicidades parciais ou concatenar campos de teste para atingir seus objetivos.
A tabela a seguir resume as diferentes técnicas para aumentar a eficácia da análise de duplicidade parcial.
Para obter mais informações sobre as funções auxiliares, consulte Funções do ajudante de duplicidades parciais.
|
Técnica |
Recurso do Analytics |
Detalhes |
|---|---|---|
|
Limitar o tamanho do conjunto de dados |
Filtros Extrair subconjunto de dados |
Reduzir o tempo de execução processando apenas registros que são significativos para sua análise |
| Ordenar elementos individuais em valores de campos de teste |
Função SORTWORDS( ) |
Reduzir o tamanho e aumentar a precisão dos resultados minimizando a importância da posição física de elementos individuais em valores de teste Observação Embora o recurso de duplicidades parciais use a comparação baseada em caracteres, a ordenação de palavras ou elementos em valores de teste oferece o benefício de aumentar o alinhamento de caracteres entre as cadeias sendo comparadas. |
|
Remover elementos genéricos de valores de campos de teste |
Função OMIT( ) |
Reduzir o tamanho e aumentar a precisão dos resultados concentrando apenas na parte dos valores de teste em que diferenças significativas podem ocorrer |
|
Concatenar campos para aumentar a singularidade dos valores de teste |
uma expressão do Analytics usando o operador de Adição (+) |
Reduzir o tamanho e aumentar a precisão dos resultados testando valores de maior singularidade, que são produzidos através da concatenação de dois ou mais campos |
|
Gerar uma única lista exaustiva de duplicidades parciais para um valor específico nos resultados de saída de duplicidades parciais |
Função ISFUZZYDUP( ) |
Produzir uma lista conveniente e exaustiva de duplicidades parciais para um valor de saída de relevância especial para o objetivo da análise |
Devo ordenar o campo de teste?
O teste de duplicidades parciais não exige que o campo seja ordenado. A ordenação de um campo de teste antes dos testes não aumenta a eficácia da operação de duplicidades parciais de nenhuma maneira. No entanto, você pode escolher ordenar um campo de teste previamente, pois isso pode tornar os resultados de saída mais fáceis de serem sondados, e a caixa de diálogo Duplicidades parciais não inclui a opção Pré-ordenar.
Observação
Embora a ordenação de valores de campos de teste não aumente a eficácia, a ordenação de elementos individuais em valores de campos com vários elementos, como endereços, pode aumentar significativamente a eficácia. Para obter mais informações, consulte Funções do ajudante de duplicidades parciais.
Inclusão de duplicidades exatas
Ao testar duplicidades parciais, é possível incluir opcionalmente duplicidades exatas nos resultados de saída. Se estiver interessado em descobrir apenas duplicidades exatas, use o recurso de duplicidade. Para mais informações, consulte Verificar duplicidades.