Échantillonnage de variables classiques
L'échantillonnage de variables classiques est une méthode d'échantillonnage statistique pour estimer ce qui suit :
- la valeur auditée totale d'un compte ou d'une classe de transactions
- le montant total d'anomalie monétaire dans un compte ou une classe de transactions
L'échantillonnage de variables classiques fonctionne mieux avec des données financières présentant les caractéristiques suivantes :
|
un nombre modéré d'anomalies jusqu'à un grand nombre d'anomalies Par exemple, au moins 5 % des écritures présentent des anomalies. |
| des surestimations ou des sous-estimations peuvent exister |
| des écritures à valeur nulle peuvent exister |
Astuce
Pour une présentation pratique du processus de bout en bout relatif à l'échantillonnage de variables classiques dans Analytics, consultez la section Échantillonnage de variables classiques - Tutoriel.
Note
En plus des données financières, vous pouvez utiliser l'échantillonnage de variables classiques avec des données numériques présentant des caractéristiques de variables, par exemple, une quantité, des unités de temps ou d'autres unités de mesure.
Fonctionnement
L'échantillonnage de variables classiques vous permet de sélectionner et d'analyser un petit sous-ensemble d'enregistrements dans un compte D'après les résultats de l'analyse du sous-ensemble, vous pouvez estimer la valeur totale auditée du compte et du montant total d'anomalie monétaire.
Les deux estimations sont calculées sous forme de plages :
- L'estimation ponctuelle correspond au milieu d'une plage.
- La limite supérieure et la limite inférieure sont les deux extrémités d'une plage.
Vous pouvez aussi choisir de calculer une estimation ou une plage unilatérale, pourvue d'une estimation ponctuelle et d'une seule limite (supérieure ou inférieure) uniquement.
Vous comparez l'anomalie estimée à la valeur comptable du compte ou au montant de l'anomalie que vous jugez significatif et vous tirez une conclusion concernant le compte.
L'échantillonnage de variables classiques prend en charge ce type de déclaration :
- Il existe une probabilité de 95 % que la véritable valeur auditée du compte se situe entre 45 577 123,95 et 46 929 384,17, plage contenant la valeur comptable de 46 400 198,71. Par conséquent, les montants du compte sont déclarés correctement.
- Il existe une probabilité de 95 % que l'anomalie du solde du compte soit comprise entre 813 074,76 et 539 185,46, ce qui est inférieur à la précision monétaire de ±928 003,97. Par conséquent, les montants du compte sont déclarés correctement.
Présentation du processus d'échantillonnage des variables classiques
Attention
Ne pas ignorer le calcul d'une taille d'échantillon valide.
Si vous extrayez directement un échantillon d'enregistrements et que vous devinez une taille d'échantillon, il y a de fortes chances que la projection de vos résultats d'analyse ne soit pas valide et que votre conclusion définitive soit erronée.
Le processus d'échantillonnage de variables classiques comporte les étapes suivantes :
- Préparer (planifier) l'échantillon de variables classiques
- Extraire l'échantillon d'enregistrements
- Réalisez les procédures d'audit prévues sur les données échantillonnées.
- Évaluez les éléments suivants :
- si oui ou non la valeur auditée des données échantillonnées, lorsqu'elles sont projetées sur le compte dans son ensemble, se situe à l'intérieur d'une plage acceptable de la valeur comptable enregistrée
- si oui ou non les valeurs observées d'anomalie monétaire dans les données échantillonnées représentent un montant acceptable ou inacceptable d'anomalie dans le compte dans son ensemble
Les valeurs sont conservées et pré-remplies entre chaque étape
L'échantillonnage de variables classiques dans Analytics nécessite que vous saisissez les informations dans trois boîtes de dialogue distinctes et vous exécutez les commandes associées, dans cet ordre :
- Boîte de dialogue Préparer CVS
- Boîte de dialogue Échantillonner CVS
- Boîte de dialogue Évaluer CVS
À mesure que vous avancez dans ce processus, les informations d'une boîte de dialogue sont automatiquement pré-remplies dans la boîte de dialogue suivante. Le pré-remplissage fait gagner un temps précieux et supprime le risque de saisie accidentelle de valeurs incorrectes et de non-validation de l'échantillon.
Cepednant, les valeurs qui remplissent automatiquement les boîtes de dialogue Échantillonner CVS et Évaluer CVS sont uniquement stockées de manière temporaire et sont supprimées lorsque vous fermez le projet Analytics.
Régénération des valeurs d'échantillonnage de variables classiques
Dans un environnement de production, vous exécutez généralement les différentes étapes du processus d'échantillonnage de variables classiques à des moments différents. Vous pouvez utiliser l'une des méthodes suivantes pour régénérer les valeurs d'échantillonnage de variables classiques qui sont perdues lorsque vous fermez Analytics.
La première méthode est la plus simple.
- Enregistrer les commandes pré-remplies
Les résultats des étapes Préparer CVS et Échantillonner CVS incluent les commandes suivantes dans le processus classique d'échantillonnage des variables qui sont préremplies avec les valeurs requises. Enregistrez ces commandes pré-remplies dans des scripts distincts pour les utiliser plus tard.
Pour de plus amples informations, consultez la section Échantillonnage de variables classiques - Tutoriel.
- Enregistrer les commandes exécutées dans des scripts
Après avoir exécuté les étapes Préparer CVS et Échantillonner CVS, copiez les commandes CVSPREPARE et CVSSAMPLE depuis la zone d'affichage Analytics et enregistrez-les dans des scripts distincts. Vous pouvez exécuter ces scripts ultérieurement pour régénérer les valeurs d'échantillonnage des variables classiques.
L'inconvénient de cette méthode est que vous prélevez un échantillon redondant d'enregistrements.
- Récupérer les commandes exécutées dans la trace
Copiez les commandes CVSPREPARE et CVSSAMPLE depuis le trace et réexécutez-les dans la ligne de commande pour régénérer les valeurs d'échantillonnage des variables classiques.
L'inconvénient de cette méthode est qu'il peut être difficile de localiser les instances correctes des commandes dans le journal et que vous extrayez un échantillon redondant d'enregistrements.
Modification des valeurs préremplies
Généralement, vous ne devez pas modifier les valeurs d'échantillonnage de variables classiques préremplies. Modifier les valeurs préremplies peut remettre en cause la validité statistique du processus d'échantillonnage.
Attention
Mettez à jour les valeurs préremplies uniquement si vous avez les connaissances statistiques suffisantes pour comprendre la conséquence de ce changement.
Limitation de longueur numérique
Plusieurs calculs internes ont eu lieu pendant l'étape de préparation de l'échantillonnage de variables classiques. Ces calculs prennent en charge les nombres d'une longueur maximale de 17 chiffres. Si le résultat d'un calcul dépasse 17 chiffres, ce résultat ne figure pas dans la sortie et vous ne pouvez pas poursuivre le processus d'échantillonnage.
Notez que les nombres des données source d'une longueur inférieure à 17 chiffres peuvent générer des résultats de calculs internes dépassant les 17 chiffres.
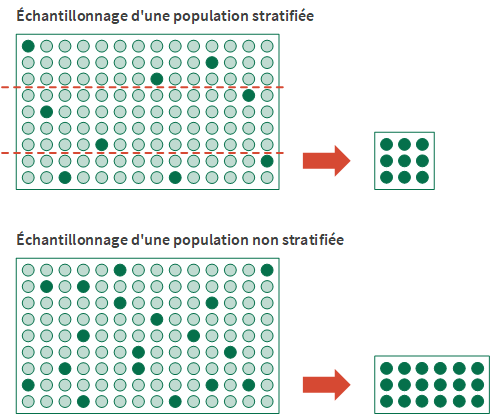
Stratification
L'échantillonnage de variables classiques vous donne la possibilité de stratifier numériquement les enregistrements d'une population avant d'en extraire un échantillon.
L'avantage de la stratification, c'est qu'elle réduit considérablement la taille requise pour l'échantillon tout en maintenant encore sa validité statistique. Disposer d'un échantillon de taille réduite implique un travail moindre sur l'analyse des données en vue d'atteindre votre objectif.
Fonctionnement
La stratification revient à diviser une population en un certain nombre de sous-groupes, ou niveaux, appelés couches. Idéalement, les valeurs de chaque couche sont relativement homogènes.
Un algorithme statistique (la méthode Neyman) définit les limites entre les couches. L'algorithme place les limites pour minimiser la dispersion des valeurs à l'intérieur de chaque couche, ce qui diminue l'effet de la variance de la population. Réduire la variance - ou l'étendue - diminue la taille d'échantillon requise. De par leur conception, la plage de chaque couche n'est pas uniforme.
Le nombre d'échantillons requis est ensuite calculé par couche, puis totalisé, plutôt qu'à partir de l'intégralité de la population non stratifiée. Pour le même jeu de données, l'approche stratifiée finit généralement par créer une taille d'échantillon plus réduite que l'approche non stratifiée.
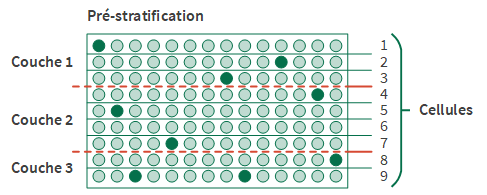
Pré-stratification à l'aide de cellules
Dans le cadre du processus de stratification, vous spécifiez le nombre de cellules à utiliser pour pré-stratifier la population. Les cellules sont des divisions numériques uniformes et plus étroites que les couches.
Un algorithme statistique utilise le compte d'enregistrements dans chaque cellule dans le cadre du calcul qui affecte les limites de couches optimales. Les cellules ne sont pas conservées dans la sortie stratifiée définitive.
Le nombre de cellules spécifiées doit être au minimum égal au nombre de couches spécifiées.
Note
Les cellules de pré-stratification et les cellules utilisées dans la méthode de sélection d'échantillon par cellules sont des choses différentes.
Il ne faut pas abuser des bonnes choses
La stratification est un outil puissant pour gérer la taille des échantillons, mais vous devez faire preuve de grande prudence lorsque vous indiquez le nombre de couches et le nombre de cellules.
Pour commencer, essayez :
- 4 à 5 couches
- 50 cellules
Après un certain stade, l'augmentation du nombre de couches - ou de cellules - n'a que peu ou pas d'impact sur la taille de l'échantillon. Toutefois, ces augmentations peuvent influer négativement sur la conception de l'échantillon ou sur les performances d'Analytics en cas de stratification de grands jeux de données.
Concernant la conception des échantillons, lorsque vous arrivez à l'étape d'évaluation, vous devez avoir un nombre d'anomalies minimal dans chaque couche afin de projeter convenablement les anomalies sur la population entière. Si le nombre de couches est trop élevé par rapport au nombre d'anomalies, des problèmes peuvent survenir avec la projection.
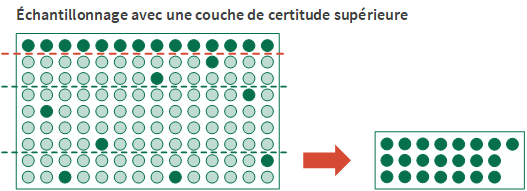
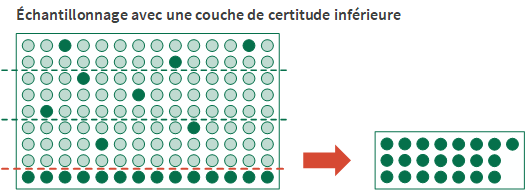
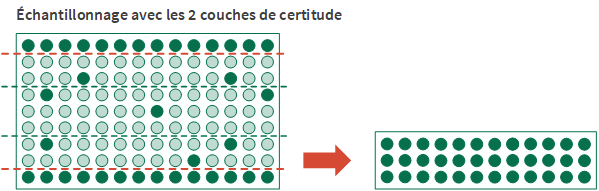
Les couches de certitude
La définition d'une couche de certitude est une autre option de stratification possible. Vous pouvez définir une couche de certitude supérieure, une couche de certitude inférieure ou les deux.
Le recours à une couche de certitude présente deux avantages :
- Inclusion automatiqueLes écritures importantes ou à valeur élevée individuellement sont incluses automatiquement dans l'échantillon et ne courent pas le risque d'être exclues par la méthode de sélection aléatoire.
- Réduction de la varianceLes écritures de la couche de certitude sont supprimées du calcul de la taille d'échantillon. De par leur nature, les écritures à valeur élevée peuvent augmenter significativement la variance de la population et la taille d'échantillon requise, si elles sont incluses dans le calcul.
Définition d'une couche de certitude
Pour définir une couche de certitude, vous spécifiez une valeur limite numérique :
- Limite de couche de certitude supérieureToutes les valeurs comptables de champs clés supérieures ou égales à la valeur limite sont sélectionnées et incluses automatiquement dans l'échantillon.
- Limite de couche de certitude inférieureToutes les valeurs comptables de champs clés inférieures ou égales à la valeur limite sont sélectionnées et incluses automatiquement dans l’échantillon.
L'utilisation d'une couche de certitude inférieure est utile si des valeurs négatives importantes sont présentes dans une population et que vous souhaitez les inclure automatiquement.
La portion de la population qui n'est pas capturée par une couche de certitude est échantillonnée à l'aide de la méthode de sélection aléatoire.
Note
Selon la nature des données, la taille globale de l'échantillon peut augmenter à mesure que vous abaissez la valeur limite pour la couche de certitude supérieure ou que vous augmentez la valeur limite pour la couche de certitude inférieure.
Vous devez éviter de fixer une valeur limite trop généreusement. Si vous ne savez pas comment définir une valeur limite, consultez un spécialiste de l'échantillonnage.
Coordination des couches de certitude supérieure et inférieure
Si vous décidez d'utiliser à la fois une couche de certitude supérieure et une couche de certitude inférieure lors du prélèvement d'un échantillon, vous devez tenir compte de la relation entre les valeurs limites supérieure et inférieure :
- Les couches de certitude ne peuvent pas se chevaucherUne erreur se produit si vous spécifiez une valeur limite supérieure inférieure à une valeur limite inférieure.
- Laisser assez d’espace entre les valeurs limitesSi vous spécifiez des valeurs limites trop proches les unes des autres, la majeure partie de la population est automatiquement incluse dans l’échantillon, ce qui va à l’encontre du but de l’échantillonnage.
Sélection des enregistrements par l'échantillonnage de variables classiques
L'échantillonnage de variables classiques utilise le processus suivant pour sélectionner des enregistrements de l'échantillon dans une table Analytics :
- Vous spécifiez un champ numérique servant de base à l'échantillonnage. L'unité d'échantillonnage est un enregistrement individuel de la table.
- À l'aide de la méthode de sélection aléatoire, Analytics sélectionne des enregistrements parmi les enregistrements de la table.
- Si vous utilisez la stratification, un nombre plus ou moins égal d'enregistrements est sélectionné de manière aléatoire dans chaque couche.
- Si vous n'utilisez pas la stratification, les enregistrements sont sélectionnés de manière aléatoire dans la population entière.
- Les enregistrements sélectionnés sont inclus dans la table de sortie de l'échantillonnage.
Exemple
Dans une table contenant 300 enregistrements, divisée en 3 couches, Analytics pourrait sélectionner les numéros d'enregistrements suivants :
| Couche 1 | Couche 2 | Couche 3 |
|---|---|---|
|
|
|
Dans une table non stratifiée contenant 300 enregistrements, Analytics pourrait sélectionner les numéros d'enregistrements affichés ci-après. Vous pouvez constater que les numéros d'enregistrements sélectionnés sont répartis de manière moins uniforme.
Note
Les numéros d'enregistrements ci-dessous sont regroupés dans trois colonnes afin de faciliter les comparaisons, mais les colonnes ne représentent pas les couches.
|
|
|
Sélection d'un échantillon non biaisé
L'échantillonnage de variables classiques est non biaisé et n'est pas basé sur les montants contenus dans un enregistrement. Chaque enregistrement a une chance égale d'être sélectionné pour être inclus dans l'échantillon. Un enregistrement contenant un montant de 1000 $, un enregistrement contenant un montant de 250 $ et un enregistrement contenant un montant de 1 $ ont tous la même chance d'être sélectionnés.
Autrement dit, la probabilité qu'un enregistrement donné soit sélectionné n'a aucun rapport avec la taille du montant qu'il contient.
Si vous voulez vous assurer que les enregistrements contenant les montants les plus élevés sont sélectionnés, consultez la section Les couches de certitude.